Dapr 是微软主导的云原生开源项目,2019年10月首次发布,到今年2月正式发布 V1.0 版本。在不到一年半的时间内,github star 数达到了 1.2 万,超过同期的 kubernetes、istio、knative 等,发展势头迅猛,业界关注度非常高。
Dapr 这个词是是 「Distributed Application runtime」的首字母缩写,非常精炼的解释了 dapr 是什么:dapr 是一个为应用提供分布式能力的运行时。
什么是 Runtime
runtime 是一个抽象的概念,字面意思是程序运行的时候。一般是指用来支持程序运行的实现。描述的是程序正常执行需要的支持:库、命令和环境等。
常见的 runtime 为程序提供的支持:
- 语言 runtime(C/Goang…):操作系统交互,垃圾回收,并发控制等
- Java runtime: 虚拟机
- 容器运行时:namespace,cgroup 等
容器运行时,就是容器运行起来需要的一系列程序和环境。比如如何使用 namespace 实现资源隔离,如何使用 cgroup 实现资源限制,这些都是容器运行时需要提供的实现。
特征:
- runtime 是在程序之外,不由程序编写者提供
- runtime 的生命周期通常和程序生命周期关联
我们写 java 程序的不需要写 java 虚拟机;构建一个容器,通常不需要去写 runc 的代码。
什么是 Distributed Application Runtime
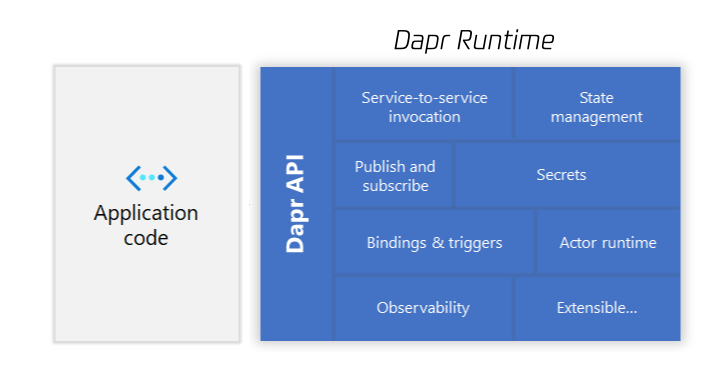
dapr 所提供的「分布式应用运行时」,是应用程序运行所需分布式能力的实现,这些能力涵盖服务通信、数据持久化、外部 binding,pub-sub 等等。比如服务调用需要有容错重试机制,比如做一个数据持久化操作是希望使用乐观锁,比如发布消息是要求有投递保证。
这些功能在之前都是集成在业务代码里的。dapr 创新之处是将这些功能,从原来 application runtime 中拆分出来,作为一个独立的 runtime。dapr runtime 也满足上面说到的runtime 的特征。
了解 service mesh 的同学可能会看出,这和 service mesh sidecar 模式很类似,这是一种让系统解耦、让开发人员关注点分离的方式。 但我们也很好奇,dapr 和 service mesh 有什么关联,这些越来越多的 sidecar 模型到底有什么区别?(knative 也用到了 sidecar 模式)。因此,在深入 dapr 之前,我们先了解一个重要的理论背景:Multi-runtime。
Multi Runtime
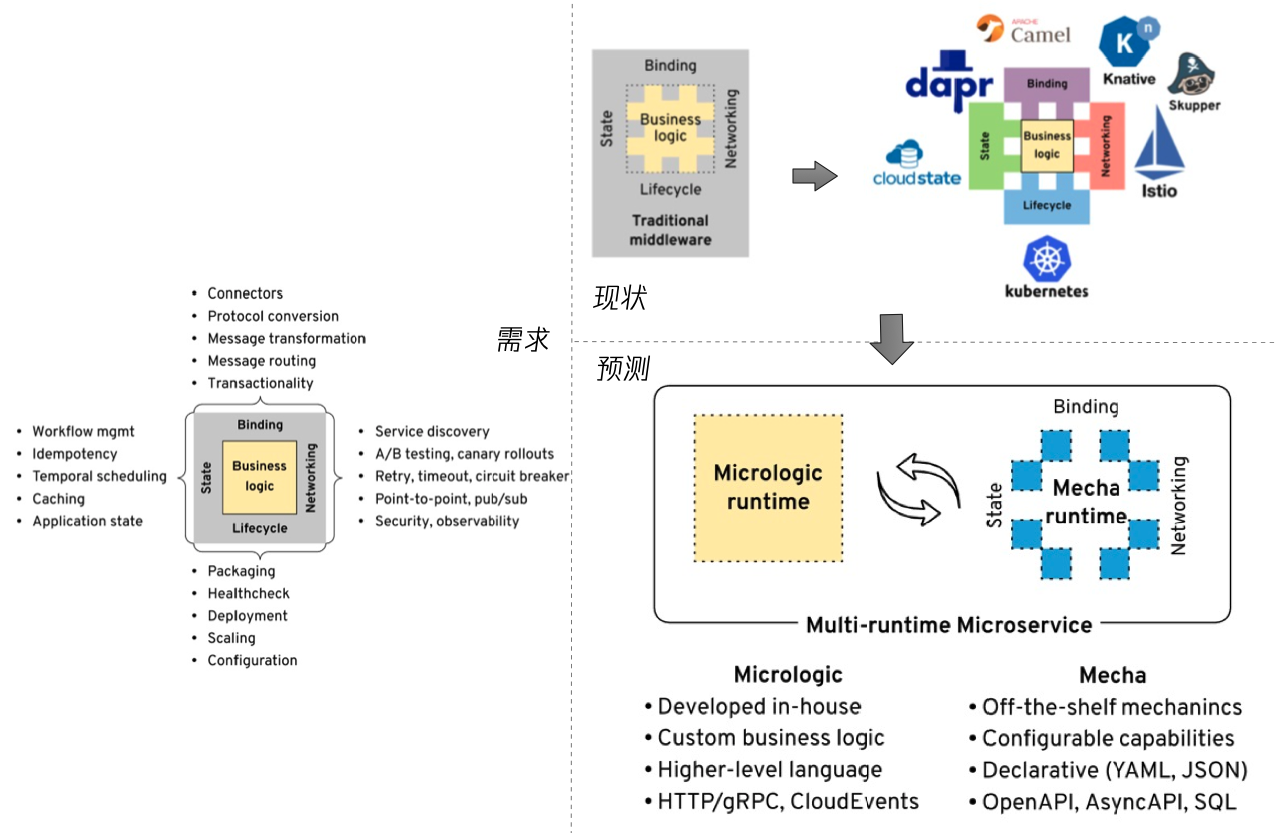
Multi runtime 是由 Red Hat首席架构师 Bilgin Ibryam 提出的,实际上 multi runtime 和 dapr 并没有直接的关系,multi runtime 的提出是在 dapr 开源之后。作者的文章重点对当今分布式应用的需求做了归类,并且分析了当前流行的云原生项目是如何满足这些分布式需求,包括 kubernetes,istio,dapr 等,最后,作者对分布式应用和中间件的未来发展,做了推导和预测,这就是 multi runtime。
分布式应用的需求:
- 生命周期:包括部署,健康检查,水平扩展,配置管理等,目前这些需求的最佳实践,都陆续在 kubernetes 上有了落地。
- 网络:网络方面的需求 是 service Mesh 的主战场,比如 istio 可以满足这里绝大部分需求,除了 pub/sub。
- 状态:包括数据的读写,状态其实是非常难以管理的,涉及幂等,缓存,数据流等等。
- 绑定:主要是指和系统外部资源的交互,包括输入绑定和输入绑定。
左边的这些需求,在传统软件时代,是耦合在应用代码里的,但现如今,有越来越多的分布式能力从应用中剥离,而剥离的方式也在逐渐变化,从最早期,这些分布式能力从业务代码剥离到库文件中,然后有一些特性剥离到平台层(kubernetes)。 而如今会有更多的非业务能力,剥离到 sidecar 中。
作者预测:理论上每个微服务可以有多个runtime: 一个业务运行时,和多个分布式能力运行时,但最理想的情况是,或者最可能出现的情况是:在业务之外的运行时合并为一个,通过高度模块化、标准化和可配置的方式,给业务提供所有分布式能力。
原文:Multi-runtime Microservices Architecture
Dapr 是什么
dapr is a portable,event-driven runtime that makes it easy for any developer to build resilient,stateless and stateful applications that run on the cloud and edge and embraces the diversity of languages and developer frameworks.
关键字:可移植,事件驱动,弹性,有状态和无状态,云和边端,语言无关,框架无关。
这些主要是 dapr 的愿景,核心是要提供一个有标准,可配置,包含各种分布式能力的运行时
Dapr 架构

dapr 的设计是典型的分层架构,其核心理念,是利用抽象层来实现应用关注点的分离,用以降低分布式应用的复杂性。
在 dapr 的架构中,核心的三个组成部分:API,Building Blocks 和 Components。
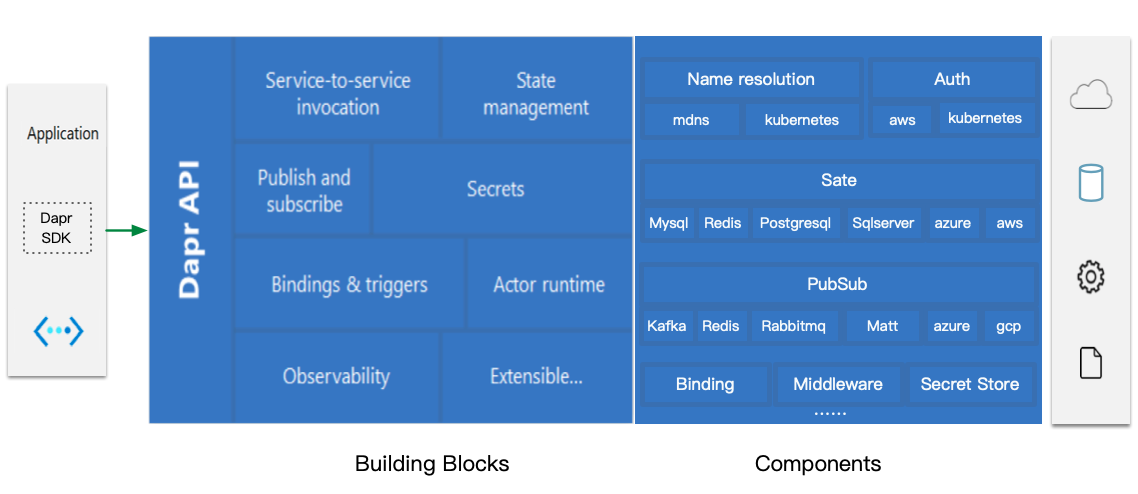
Dapr Building Blocks
这是 dapr 对外提供能力的基本单元,是对分布式能力的抽象和归类,包括以下几大类
- service-to-service invocation
- State management
- Publish and subscribe
- Resource bindings
- Actors
- Observability
- Secrets
这些都是和应用开发息息相关的。 每一种 building block 都是完全独立的,应用可以按需调用。
我们可以对比下 dapr building blocks 和之前 multi runtime 提出的4大类 分布式能力需求,lifecycle,networking,state,binding。 其中 lifecycle 不属于 runtime 范畴,lifecycle 能力通常使用平台提供,目前云原生领域基本上是被 kubernetes 垄断,除此之外的 networking,state 和 binding 都包括在 dapr 的 building blocks 中。
Dapr Components
Components 提供和各种分布式实现的对接,包括自建的,云上的,边缘等等。
理论上 building block 可以组合使用任意的 components,一个 component 也可以被不同的 building block 使用。比如 actors 和 state 都会使用 state component; 另一个例子,service invocation 会使用 name resolution,和 middleware component,而且不同的场景下,可以选择不同的 component 实现。
Component 类型和实现: 在实现层面,每一种 component 类型 定义了一系列接口(interface definition),每一种 component 类型 有多种 component 实现,他们都实现了 component 类型要求的接口(interface)。
Dapr API
应用如何能使用到这些分布式能力,这是 dapr 最核心的设计,也是 dapr 应用和非 dapr 应用最关键的区别: dapr 利用标准 API 暴露各种分布式能力。API 定义了应用所需的分布式能力。dapr 提供两种API: HTTP1.1/REST 和 HTTP2/gRPC,两者在功能上是等价的。这些 API 是平台无关的,或者说是实现无关的,这是 dapr 能否流行的一个关键。
应用只需要按照 API 规范发起,不管是服务访问,还是存储,还是发布消息到队列里,都是 HTTP 接口。 不管是写 redis ,还是写 mysql 都是一样的API,开发能正在的实现面向接口编程。 在应用看来,一切所需的能力,都可以用 HTTP 协议来表示,这些能力的获取是标准化的,只要应用需要的分布式能力不变,那应用的代码就不需要改变。
将「分布式原语」映射到 http API 上,极大地减少了程序员心智的开销。在应用代码中不再需要引入相关的组件调用库,不需要去封装组件的具体调用方式,不需要对不同的实现做区分。
另外在用户应用侧,dapr 还提供了多种语言的 SDK,这些 SDK 的目的是用更便捷的方式来暴露 Building Blocks 的 API,用更加语义化的方法调用,来封装 http/gRPC 的调用。
总结:
- API: 通过标准化的方式暴露 Building Block
- Building Block: 是能力的抽象
- Components: 对接能力的实现
API 调用是如何实现
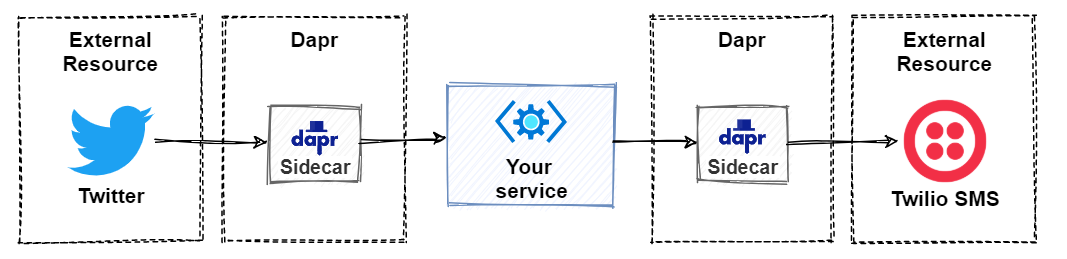
一个存储调用的例子:比如一个电商系统,需要持久化存储,传统的做法是,我们要先决策使用什么存储,mysql 或者 redis 等,我们需要在代码里引入相应的 SDK,编写各异的实现,未来如果应用想要切换存储类型,或者从本地存储迁移到云上,改动非常大。
假设这个系统的特征是读多写少,那我们倾向于用乐观锁来更新数据。业务提出来的「用乐观锁控制并发写入」这就是一个典型的分布式需求,而这种需求的实现在不同的存储系统中不尽相同,比如 mysql 是需要用户显式指定一个字段作为版本信息,用户写操作是需要把版本信息传回,而 redis 乐观锁是用户指定在 redis server 端 watch 某个 key。类似的需求还有数据库一致性,是使用最终一致性还是强一致性,各种存储实现也不同。
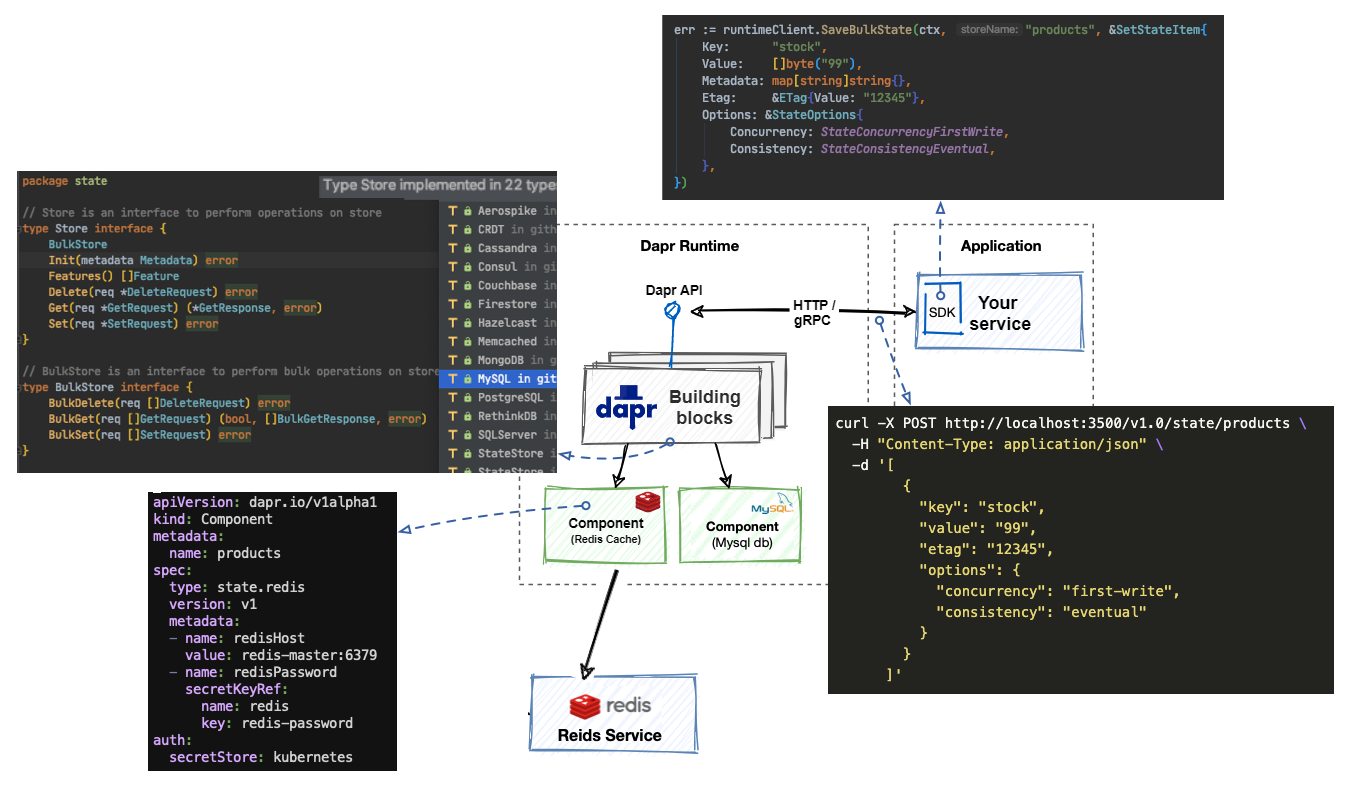
如上图所示,如果接入使用 dapr runtime,应用发起存储调用非常简单,不需要在应用代码里引入 redis 或者 mysql 的 SDK,也不用关心实际存储使用是什么通信协议,应用代码里只需要使用分布式原语和 dapr runtime 通信,通信的协议是简单的 http 或者 gRPC,dapr runtime 去实现这些分布式能力。
Service Invocation
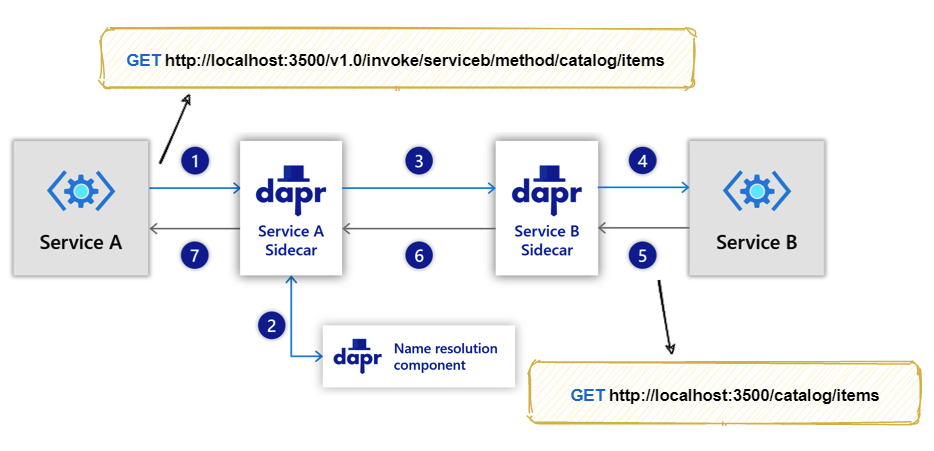
主要能力:
- 服务发现
- 通信安全
- 失败重试
- 可观测性
在 kubernetes 中使用 dapr,dapr 会为每个服务生成一个新的 service (以-dapr结尾),sidecar 之间的通信都是 gRPC,每个应用需要指定一个 app-id 用于服务发现,应用需要显示的发起对 runtime API 的调用,没有类似 mesh 的 iptables 透明拦截。
大家可以脑洞一下,如果 dapr 这种模式能大规模流行,那市面上大部分 RPC 是不是都不再需要了,如今大部分RPC虽然各有个特点,但是大部分功能都是类似的,服务发现,编解码,网络传输。有的 RPC 框架还带 服务治理的能力,大部分能力目前都可以由 mesh 或者 dapr 这类 runtime 来提供。
State management
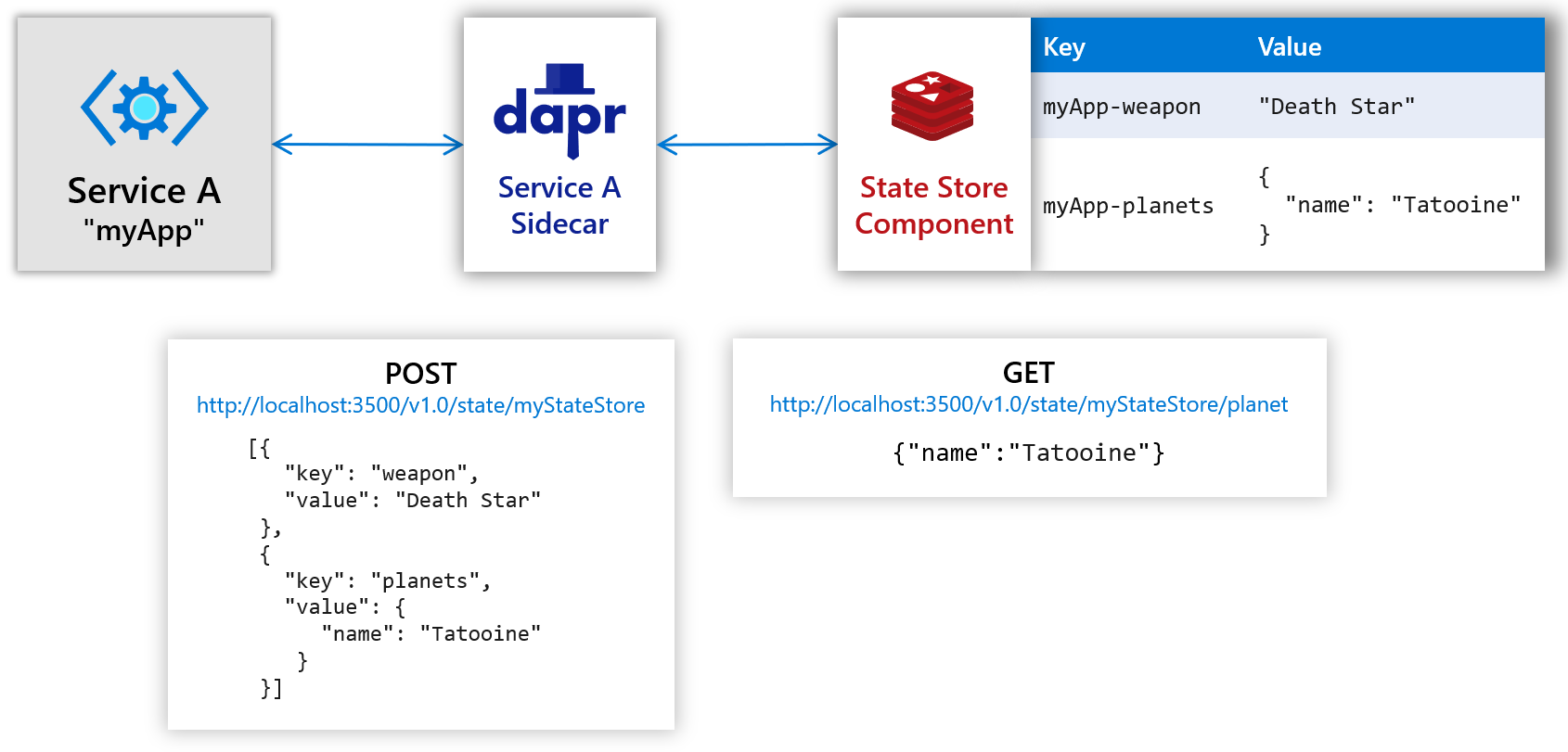
主要能力:
- CRUD,包括批量操作
- 事务
- 并发:first-write-wins、last-write-wins
- 一致性:最终一致、强一致性
- 可插拔 (Pluggable state stores)
State 提供一致的键值对存储抽象,这里不包括关系型或者其他类型的存储。 总的来说,在云原生领域(以 kubernetes 和 etcd 为代表),键值对存储的适用范围更广。另外相比其他存储类型,键值对存储引擎的接口抽象更容易实现,即使是关系型数据库,也能轻松的实现对键值对 API 的支持。
但仍然不是所有的存储引擎都能提供等价的键值对存储能力(见存储实现差异)。 为了保证应用程序的可移植性,这里的确是需要一些适配工作。 比如像 Memcached,Cassandra 这些是不支持事务的,而很多数据库也不能提供基于ETag 的乐观锁能力。
对于并发控制,在 API 层,dapr 利用 HTTP ETags 来实现并发控制,类似 kubernetes 对象的 resource version,具体地:dapr 在返回数据时,始终会带上 Etag 属性。 如果用户需要使用乐观锁做更新操作,请求中需要带回 Etag,只有当 Etag 和服务器上数据的相同时,更新操作才会成功。如果更新操作没有带上 Etag,那并发模式将是 last-write-wins。
Publish and subscribe
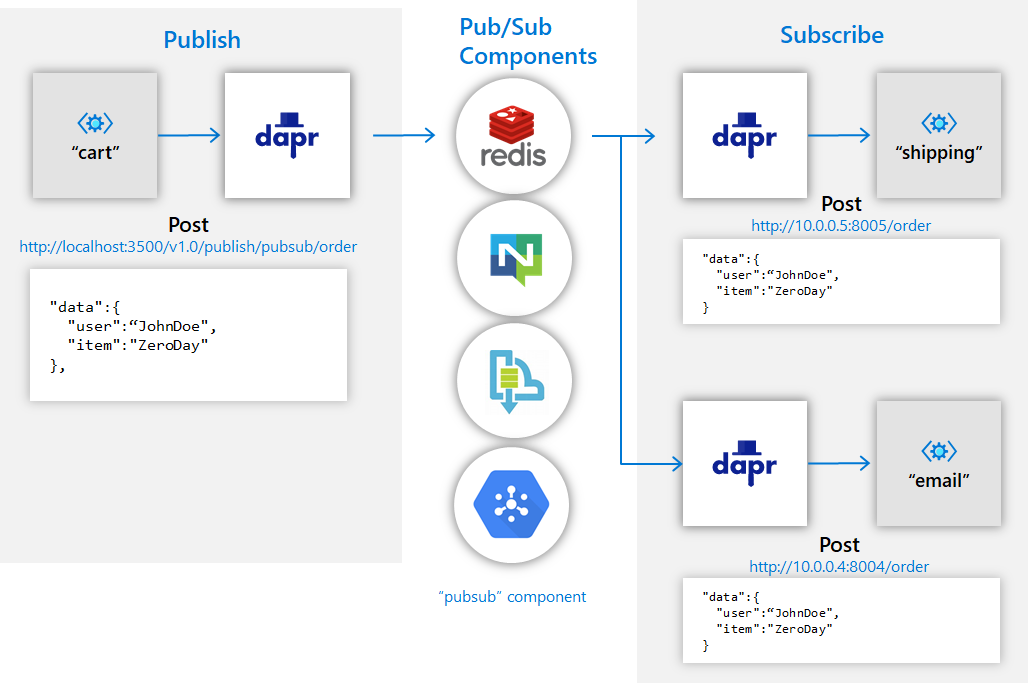
使用发布和订阅模式,微服务间可以充分的解耦。
主要能力:
- 统一的消息格式:Cloud Events
- At-Least-Once guarantees( 消息绝不会丢,但可能会重复传递)
- 支持消息过期时间(per message TTL)
- 支持 topic 可见性配置
Runtime 不仅可以做能力的对接适配,还可以做增强,这是一个例子: 如果消息组件原生支持消息有效期,那 runtime 直接转发 TTL 相关操作,过期的行为由组件直接控制,而对于那些不支持消息有效期的组件,dapr 会在 runtime 中补齐相关的过期功能。(CloudEvent 里有 expiration)
两种订阅方式

二者提供的功能是一致的。外部声明方式需要多维护一个 CRD 对象,适合订阅者或订阅主题经常发生变化的场景,这样在调整时不需要改应用代码。应用编码方式刚好相反,订阅配置写死在代码里,适合订阅主题不需要动态调整的场景。
Bindings
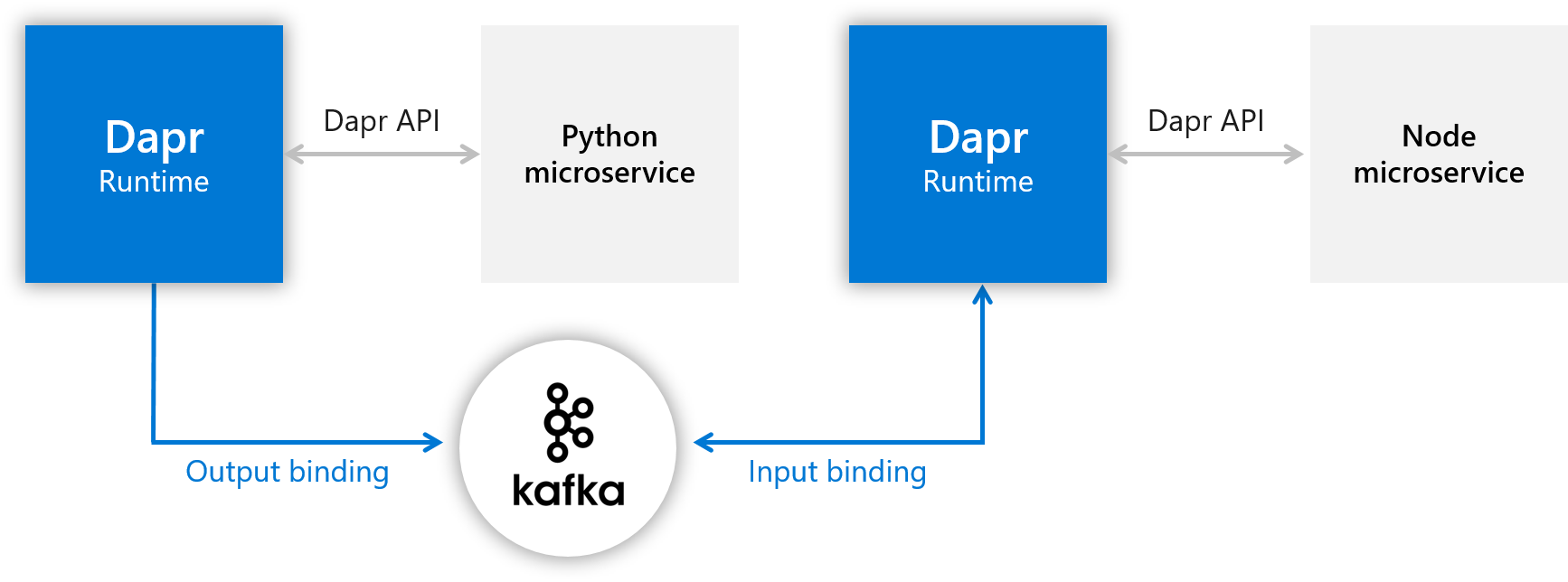
Bindings 其实和之前的 pub/sub 非常类似,也是利用异步通信传递消息。它俩主要的区别是:pub/sub 主要面向的是 dapr 内部应用,而 bindings 主要解决的和外部依赖系统的输入输出。
实际上它俩下层的 components 有很多是重叠的,比如说 kafka,redis 既可以作为内部消息传递,也可以作为外部消息传递。 pub/sub 基本可以等同于消息队列,但 bindings 主要是处理事件(trigger handler),比如 twitter 关键字事件,比如 github webhooks。
Actor
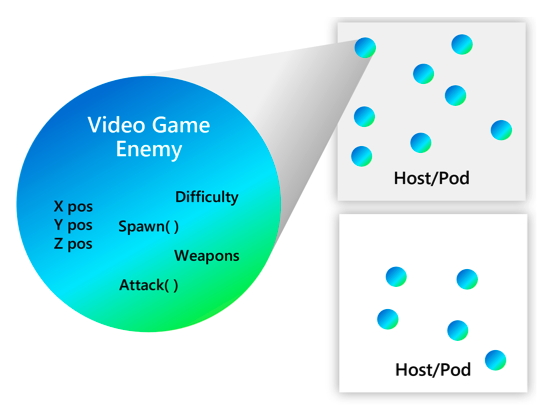
- 最基本的计算单元,封装了可以执行的行为和私有状态
- 通过信箱异步通信
- 内部单线程
- 虚拟的:不需要显示创建,自动 GC
Actor 是一种并发编程的模型,Actor 表示的是一个最基本的计算单元,封装了可以执行的行为和私有状态。
actor 之间相互隔离,它们并不互相共享内存,也就是说,一个 actor 能维持一个私有的状态,并且这个状态不可能被另一个actor所改变。在 actor 模型里每个 actor 都有地址(信箱),所以它们才能够相互发送消息。每个 actor 只能顺序地处理消息。单个actor不考虑并发。
Dapr 中 actor 是虚拟的,它们并不一定要常驻内存。 它们不需要显式创建或销毁。 dapr actor 运行时在第一次接收到该 actor ID 的请求时自动激活 actor。 如果该 actor 在一段时间内未被使用,那么 dapr actor 运行时将回收内存对象。 如果以后需要重新启动,它还将还原 Actor 的一切原有数据。
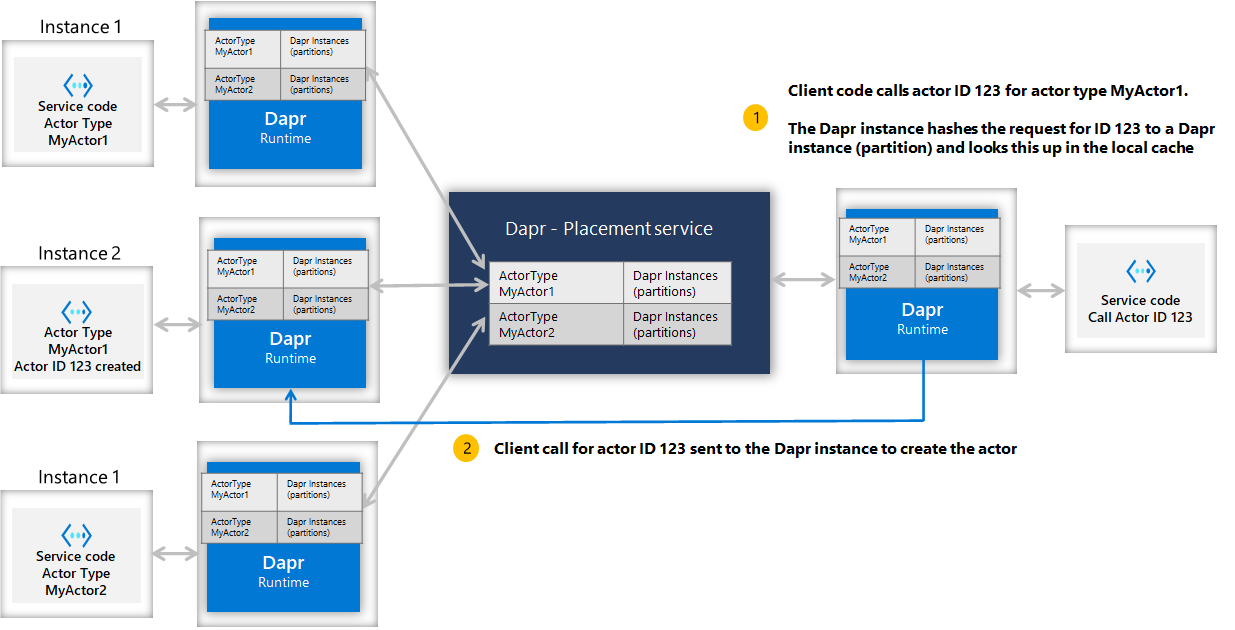
Actor placement service 为系统提供了 actor 分发和管理,placement 会跟踪 actor 类型和所有实例的分区,并将这些分区信息同步到每个 dapr 实例中,并跟踪他们的创建和销毁。
Middleware Pipelines
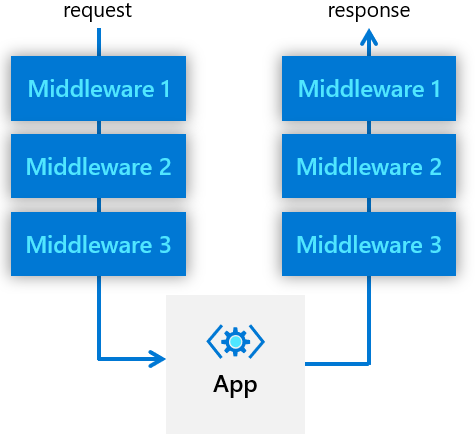
注意 middleware pipelines 是一个 component 类型,而不是 building block。
Dapr 官方提供流量管控的能力比较弱,和 istio 相比的话,目前 dapr 只有重试,加密等少数的管控能力,但 dapr 提供一个扩展的方式:这就是 middleware pipelines,用户可以按需编写不同的实现,并把他们级联起来使用。
其实这种方式在各种编程语言 web 框架中非常常见,只是叫法不同,有的叫装饰者模型,有的叫洋葱模型,其实模式都是一样:请求在路由到用户代码之前,会先按序执行预定义 middleware pipelines,请求经过应用处理后,再按相反顺序执行上述 middleware pipeline。通常在前序中对 request 做相应的增强处理,在后续中对 response做增强处理。
咋一看这可能是一个不太起眼的功能,但和传统 web 框架的middleware不一样, dapr runtime 本身是在应用进程之外,所以不存在语言限制的问题。这使得 middleware 提供的功能可以跨语言共享。比如 dapr 原生没有提供限流和自定义鉴权的功能(呼声很高的2个场景),我们可以遵循 middleware 的接口按需实现,然后植入 dapr 运行时中。

部署模式
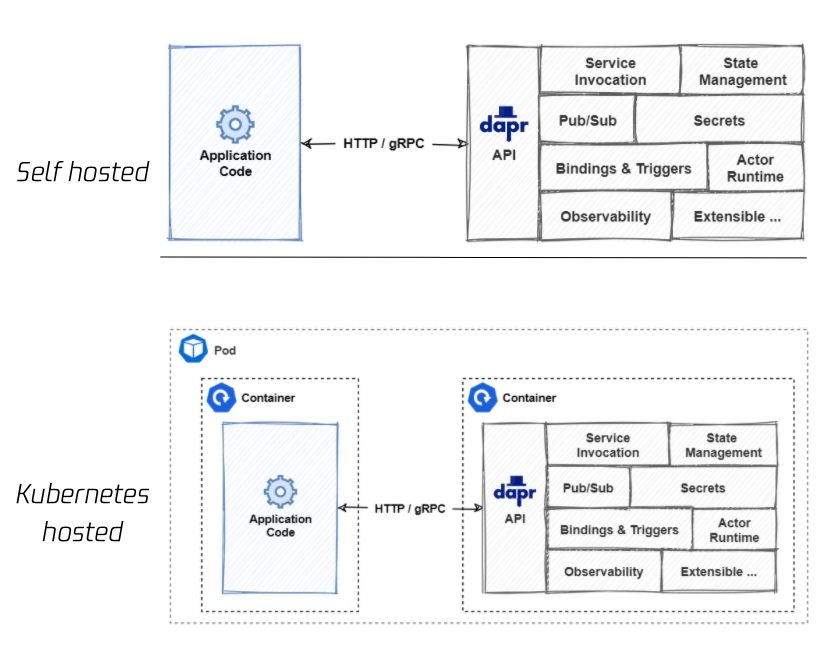
Dapr 使用 sidecar 模式来暴露 building blocks 的能力,这里的 sidecar 除了包括 sidecar container外,还可以是 sidecar process。
在非容器化环境中,用户应用和 dapr runtime 都是独立的进程;而在 kubernetes 这种容器化环境中,dapr runtime 作为 sidecar container 注入到 业务pod 中,这和 service mesh sidecar 模式是一致的。
控制面
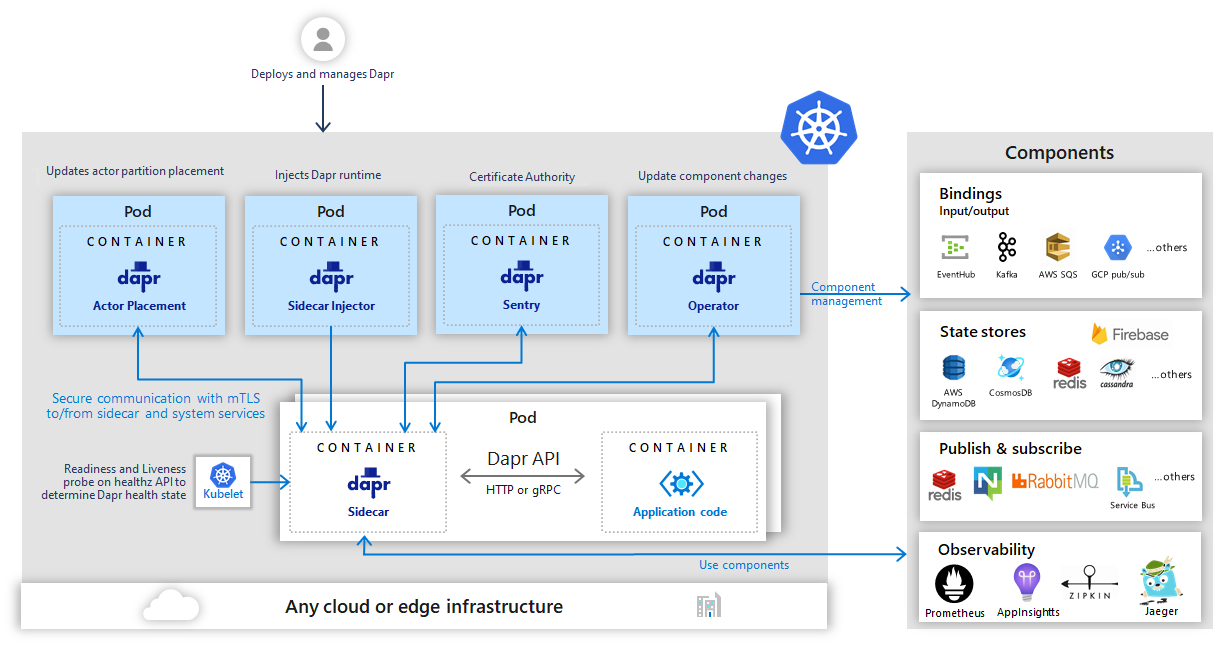
整个控制面还是一个微服务。和 istio 早期有点类似。
Sidecar injector:利用 kubernetes mutating webhook 给业务 pod 注入 dapr runtime sidecar 容器,以及运行所需的环境变量,启动参数等。包括连接控制面 oprator 的地址(control-plane-address)等。
Operator:会 list watch 用户定义的 Component 资源,并下发给数据的 dapr runtime。数据面 runtime 会持有一个 OperatorClient 去 连接控制面 Operator。
Sentry: 为 dapr 系统中的工作负载提供基于 mtls 的安全通信。mtls 能强制通信双方进行身份认证,同时在认证之后保证通信都走加密通道。Sentry 的功能很类似 istio 里的 Citadel (目前已经合并到 istiod)。在整个过程中,sentry 充当证书颁发机构(CA),处理 dapr sidecar 发起的签署证书请求,另外还要负责证书的轮转。除了 dapr sidecar 之间的自动 mTLS 之外,sidecar 和 dapr 控制面服务之间也是强制性的 mTLS。
Placement:用于跟踪 actor 的类型和实例分布,并同步给数据面的 runtime。
性能
sidecar 模式会带来额外的性能开销。 以我们使用 service mesh 的经验来看,这种模式的性能开销主要是2个方面,一个是流量经过 sidecar 的拦截、流量管控和转发损耗,另一个是 sidecar 需要从控制面同步管理数据,sidecar 需要存储和处理这些数据,这可能会给数据面内存和 CPU 带来压力,特别是大规模场景下。
在官方对 dapr V1.0 的性能测试数据看: 在不开启 mtls 和 遥测的情况下,延迟 P90 大概增加 1.4 ms,在开启 mtls 和 0.1 tracing rate 情况下,P90 数据大概还会增加了 3ms 左右。
这个数据要比 istio 好,dapr sidecar 没有太多的流量管控和修改的功能,也没有使用 iptables 拦截,开销相对较小。 为了尽可能提高通信效率,dapr sidecar 之间的通信固定使用 gRPC 协议。 而且 dapr 从数据面同步的数据量也非常少,所以也不会有类似 istio 场景下频繁 reload xDS 的问题。
但相比 service mesh,dapr sidecar 管控了更多的流量类型,比如状态存储,应用系统对这类流量的延迟变化更加敏感,用户在接入 dapr 之前需要慎重评估。目前dapr 还在项目初期,业界还没有太多大规模,精细化的落地测评。
和 Service Mesh 比较
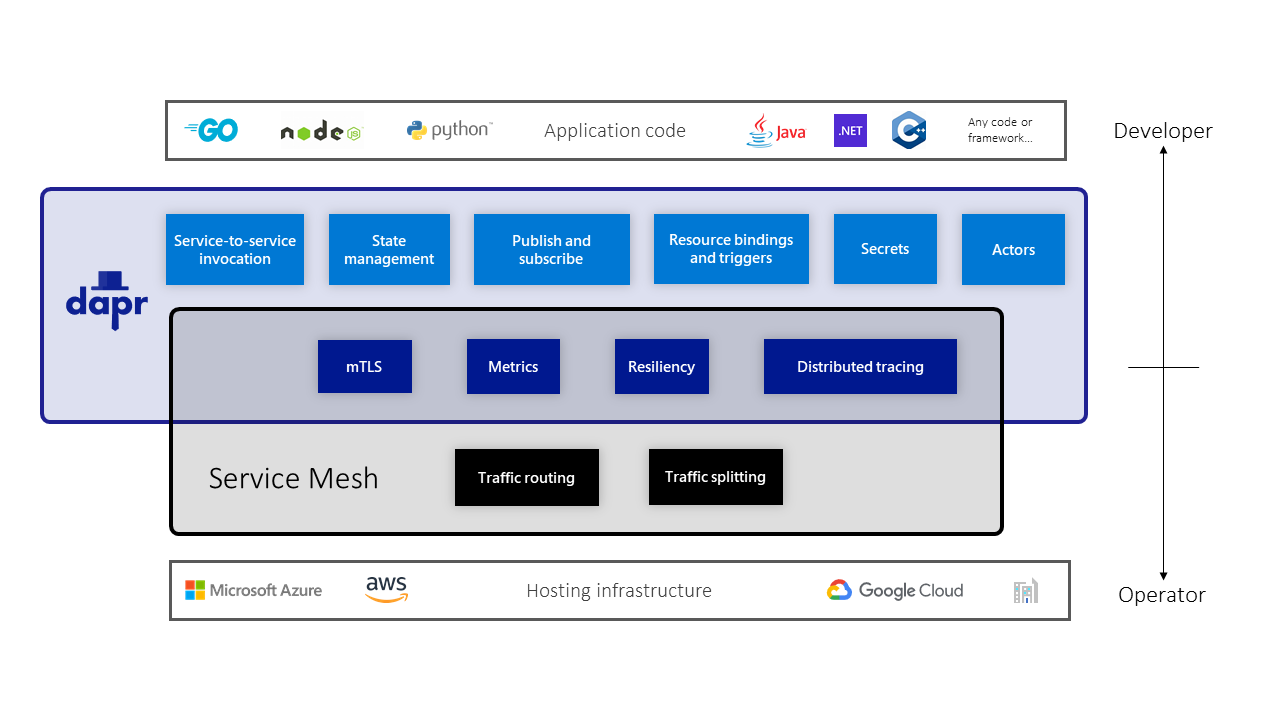
二者都使用了 sidecar 模式,功能上也有重叠,二者理论上是可以共存的,虽然同时使用这2种技术不是一个最优的方案(开销和维护成本)。
Service mesh 定位偏向于服务级别的网络基础设施层。Service mesh 做了很多努力来让 mesh 层对应用层透明,期望服务能平滑的迁移。理想的情况下,应用开发者应该不感知 mesh 层的存在,所以 mesh 面向的主要是系统运维人员和传统中间件团队。
Dapr 旨在提供应用所需要的分布式能力,这些能力是和业务的正常运作息息相关的, dapr 提供的能力不是透明的,是需要应用显示的调用,所以 dapr 主要面向的开发人员。
服务调用方面,mesh 使用透明转发,对应用程序友好,但是支持的协议有限,mesh 对七层的协议扩展一直是一个难点。 而在 dapr 里必须显示发起调用,所有调用都是会转为 gRPC,不需要考虑协议扩展。
一些重叠的功能点:
- 服务通信 mTLS
- 遥测
- 重试
我们拿 istio 和 dapr 做一个比较:
istio 有强大的流量管控能力,这些是 dapr 不具备的。在 istio 数据面中,每个 envoy 都同步获取了整个网格内服务信息(通过 xDS)的全貌,包括服务所有的 endpoint IP,以及这些 endpoint 的特征,这让 istio 可以实现很多复杂的负载均衡场景。
而 dapr sidecar 没有实现类似的能力,在 kubernetes 平台下,dapr 应用间的服务互访,还是依赖 kubernetes service 提供的随机负载均衡。这是 dapr 的短板,dapr runtime 不感知其他 endpoint 的信息, 因此 dapr 甚至不能提供 round robin 的负载均衡策略。
Dapr 的核心功能是为应用提供了标准化的分布式能力,诸如状态管理,订阅发布,Actor 等等,这些领域 istio 基本不涉及。
另外在遥测领域,二者也有区别,istio 的遥测主要是集中在服务间调用,而 dapr 除了能观察服务间调用,还把观测范围扩展到了 pub/sub 领域,这得益于 dapr 使用 cloud events 格式来传递 pub-sub 消息,这样 dapr 可以将 metrics 和 tracing 信息写入 cloud events 进行传递。
另外目前 dapr 在 kubernetes 的控制面是微服务,而 Isito 控制面已经是一个单体,未来 dapr 控制面有可能也会合并成一个单体。
总结
虽然前面我们分析了 dapr 这种 multi runtime 出现的背景和趋势,但仍不得不说 dapr 的设计非常的新颖。dapr 的创新之处在于提供标准化的分布式能力 API,这一点既是开发人员非常欢迎的模式,但也是业务接入最大的挑战,因为这涉及到项目的改造甚至重写。
我想应该有不少程序员都做过这样的「美梦」: 我不想了解依赖系统各种复杂的差异,我只想面向接口编程、面向抽象编程。 如今 dapr 把这种理想化的架构模式初步实现了,这也是为什么 dapr 目前虽然还不是很成熟,但已经吸引了大量开发者的关注。接下来随着社区的积极投入,dapr 的生态会更加完善。