随着容器技术的流行,大量互联网公司和传统 IT 企业都在尝试应用容器化和服务上云。容器化是一个持续的过程,伴随着多地域部署、安全等级隔离、多云和混合云等复杂的场景需求。
上篇文章中我们成功将广州和新加坡 2 地的 kubernetes 集群连通为一个服务网格,实现了多集群服务透明共享:recommend v1 和 recommend v2 分别部署在广州和新加坡地域, 但是两地用户都可以无差别的访问到任一版本。
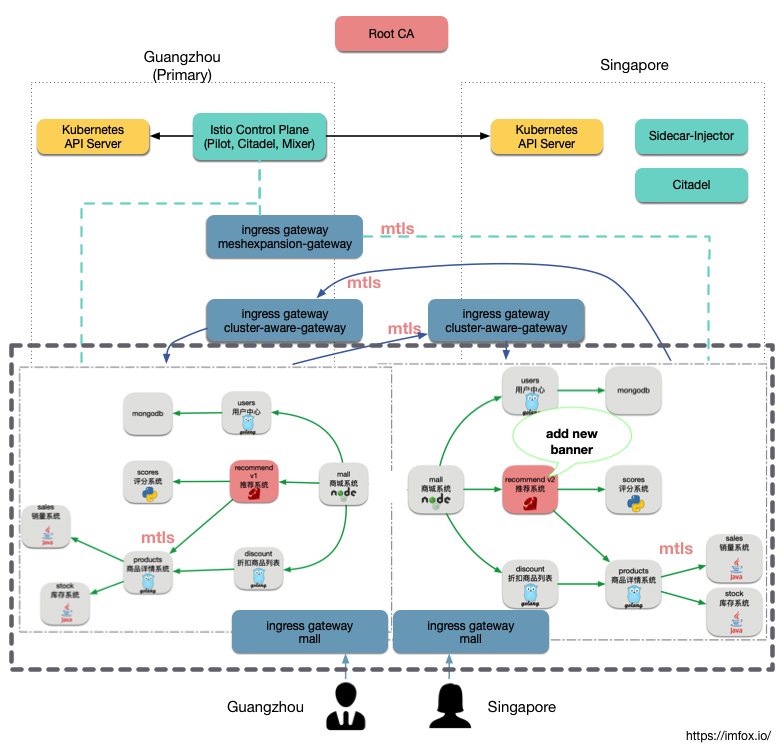
接下来我们上述环境中, 尝试几个多集群服务网格的应用场景,包括:
-
异地容灾
-
地域感知负载均衡
-
多地域负载策略分析
相关代码汇总于:zhongfox/multicluster-demo
异地容灾
要保证系统高可用和良好的用户体验,服务多副本部署、特别是异地多副本部署是必不可少的架构, 即使对于吞吐量低压力小的应用,考虑「墨菲定律」单点部署仍是应该尽量避免的。对于 SLA 要求较高的关键系统,两地部署甚至多地部署应对容灾也是非常必要的。
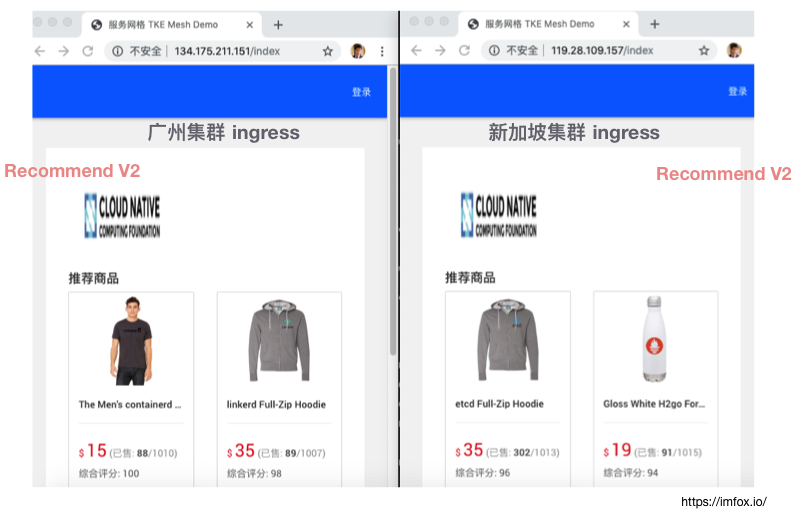
在已部署的环境中, 我们尝试将广州集群中的 recommend v1 服务副本数删除至 0 个,模拟广州集群 recommend 服务实例不可用:

这时候我们分别多次访问广州和新加坡商城应用, 发现任一入口访问, 页面都可以正常显示, 且「推荐商品」板块显示的都是 recommend v2 版本, 也就是部署在新加坡地域的有 banner 的版本:
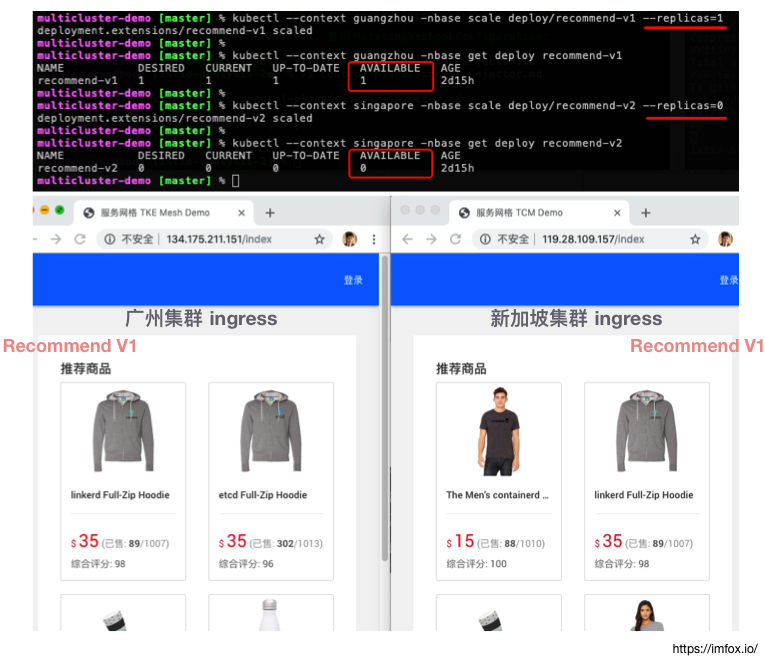
现在我们把广州集群 recommend v1 服务恢复为 1 个副本,将新加坡集群 recommend v2 服务副本数降至 0,类似的, 我们可以验证, 两地访问商城应用, 页面显示都正常,而且显示的都是广州集群无 banner 的 recommend v1 版本:
地域感知负载均衡
在多地域部署架构中,地域感知负载均衡需求主要源自以下需求:
- 在跨地域部署的多集群中,各地域可能会部署本地区定制化的服务,比如不同地区的服务会有不同的显示语言或定制功能,或者某些服务只在特定区域开放。这些场景要求服务间的访问不能随机路由,需要优先(或只能)访问本地域服务。
- 在用作容灾在多地域架构中, 往往会有一个主集群, 拥有较为充足的服务资源, 而容灾地域的资源仅保证服务基本可用。因此我们要求正常情况下,请求能由主集群提供服务,流量不要地域间随机路由。
- 即使不是以上场景,考虑 2 个异地对等集群,提供服务和持有资源完全相同, 我们也应该尽量满足本地域内闭环服务, 因为跨地域的服务访问往往会有较大的延迟,用户体验差, 且可能会让容错性较差的系统出现服务雪崩的风险。
Locality Load Balancing 是 istio 1.1 增加的 experimental 特性,接下来我们在上述环境中验证此特性:
首先我们先还原上个场景的修改,将广州地域和新加坡地域的 recommend 服务副本都设置为 1:
% kubectl --context guangzhou -nbase scale deploy/recommend-v1 --replicas=1
% kubectl --context singapore -nbase scale deploy/recommend-v2 --replicas=1
然后开启 Locality Load Balancing:设置 Pilot 的环境变量:
% kubectl -n istio-system --context guangzhou edit deploy istio-pilot
......
env:
- name: PILOT_ENABLE_LOCALITY_LOAD_BALANCING
value: "ON"
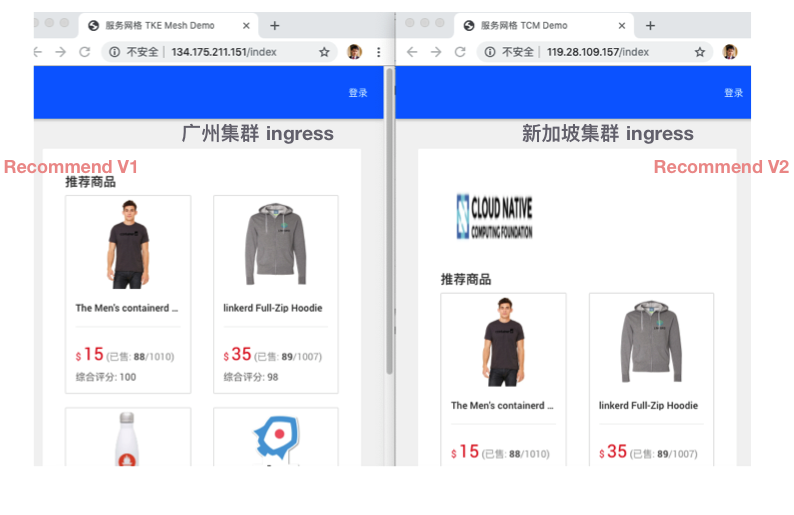
稍等片刻,分别通过广州和新加坡地域入口多次访问商城应用,可以发现广州入口一直展示 recommend v1 版本,新加坡地域一直展示 recommend v2 版本:
开启「地域感知负载均衡」后, 因为流量都在同一个集群中,所以访问速度开启之前,会提升很多,我们实测一下, 在开启「地域感知负载均衡」前后,使用 ab 工具, 模拟访问 2 个地域各 100 次:
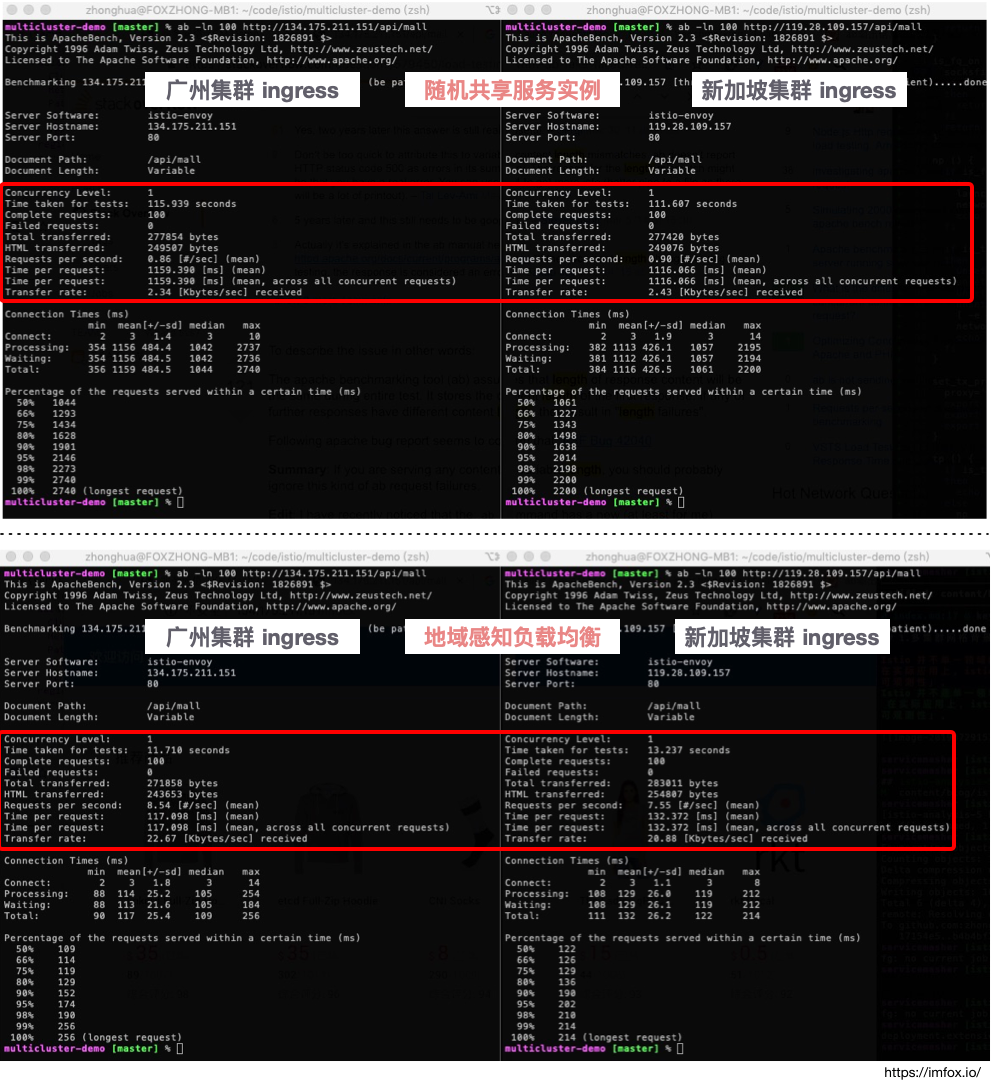
上图所示,开启「地域感知负载均衡」功能后,请求平均耗时从大概 1116~ 1159 毫秒下降到了 117~132 毫秒。
多地域负载策略分析
在 kubernetes 平台, istio 根据 kubernetes node 上的约定地域标签,来确定 node 上包含的 pod 的地域亲和度, 在 TKE 上, node 默认有了地域标签:
~ % kubectl --context guangzhou get node --show-labels
NAME
172.16.48.35 ......
failure-domain.beta.kubernetes.io/region=gz,
failure-domain.beta.kubernetes.io/zone=100002
~ % kubectl --context singapore get node --show-labels
NAME
172.22.0.42 ......
failure-domain.beta.kubernetes.io/region=sg,
failure-domain.beta.kubernetes.io/zone=900001
failure-domain.beta.kubernetes.io/region表示地域, failure-domain.beta.kubernetes.io/zone表示可用区。
地域负载均衡默认会使用地域优先策略,具体讲,一个具体区域的 envoy 会将其他实例做如下优先级处理:
- Priority 0 最高优先级:相同地域且相同区域
- Priority 1 第二优先级:相同地域但不同区域
- Priority 2 最低优先级:不同地域
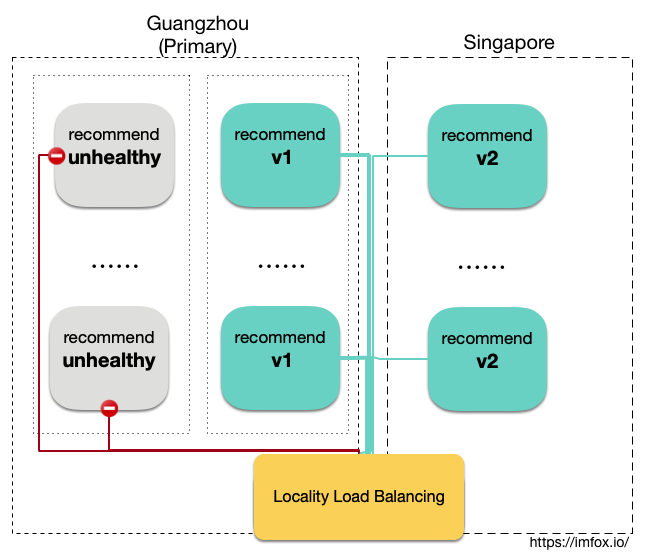
考虑开启「地域感知负载均衡」后, 整个服务网格如何做失效转移:
为了减少低效的跨地域访问,istio 会尽量保证按照地域优先级负载均衡;但是当本地域服务的可用性降低时,流量应该适当的转移一部分到下一优先级的地域去,流量的转移应该尽量平滑。流量转移的时机不应该等到本区域服务可用性降至零后才开始, 因为这会有服务中断甚至雪崩的风险。
在 envoy 负载均衡策略中,有一个很重要的参数:Overprovisioning Factor 可以翻译为 「预留资源」参数,区域流量降级的时机和比例,会受到本区域的「服务可用性」和「预留资源」参数共同决定。istio 中「预留资源」参数默认是 1.4。
可以这样理解「预留资源」参数:指定区域部署的服务资源, 通常会高于系统实际需要的服务资源,以应对可能出现的各种异常导致的可用性降低。比如本区域 recommend 服务预估 100 副本可以满足用户需求,按照容灾经验我们可能会部署 140 副本。当本区域因为异常导致副本数下降,可用性降低时, 系统应该判断,只有副本数低于 100 时,才开始将多余流量转移到下一级地域。
基于以上网格环境, 我们对地域负载策略进行验证:
在广州集群中, 我们再部署一个新的 recommend deployment,名为 recommend-unhealthy,这个副本的推荐接口直接返回状态码 502,用以模拟不可用的服务实例:
get '/recommend' do
status 502
end
同时我们给 recommd 服务加上断路器:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: recommend
namespace: base
spec:
host: recommend.base.svc.cluster.local
trafficPolicy:
tls:
mode: ISTIO_MUTUAL
outlierDetection:
consecutiveErrors: 3
interval: 30s
baseEjectionTime: 3m
表示 recommend 服务实例,如果连续 3 次访问失败,将标记为不可用。不可用实例将被隔离于可用实例之外,持续 3 分钟。
以上操作可以通过执行以下命令实现:
kubectl --context guangzhou -nbase apply -f install/locality-load-balancing.yaml
广州集群 2 个 recommend 共同组成该地域的服务 endpoints, 广州 recommend 服务的健康度(可用性)可以表示为:
health = recommend-v1-replicas / (recommend-v1-replicas + recommend-unhealthy-replicas)
按照默认 Overprovisioning Factor 为 1.4,广州集群负载均衡流量百分比数为:
guangzhou-LB = min(100, 1.4 * 100 * health)
新加坡流量百分比数:
singapore-LB = 100 - guangzhou-LB
编写一个 ruby 程序 进行验证:
最初 recommend v1 副本数为 14, recommend unhealthy 副本数为 0, 一直保持 2 个 deployment 的副本总和为 14, 逐渐增加 unhealthy 副本的比重, 等待所有 pod ready 后, 使用广州网关入口发起 1000 次请求, 然后根据响应内容判断 recommend 服务的负载均衡情况:如果内容不包含 recommend banner,是由广州集群提供服务, 如果内容包括 recommend banner, 那么请求就是转移到了新加坡集群,测试结果如下图:
ruby ./install/recommend_stat.rb --ip 134.175.211.151 --count 1000
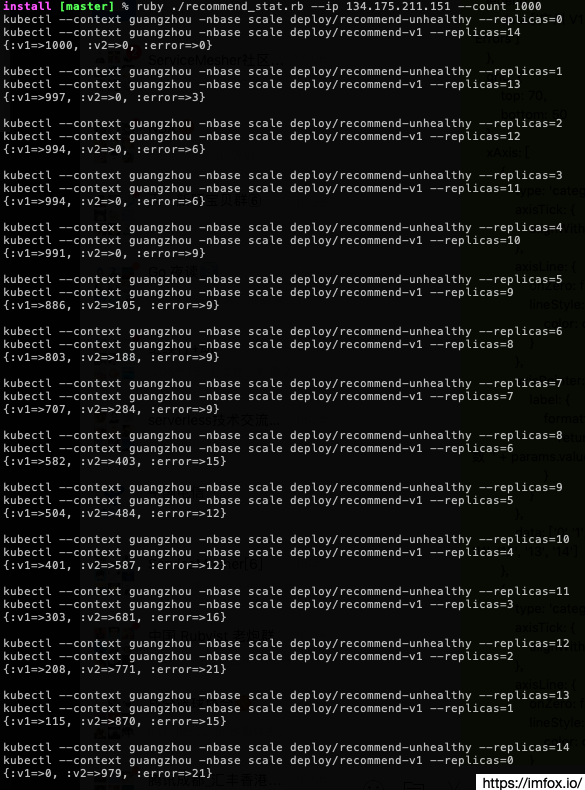
数据统计可以看出,广州健康副本(v1)由 14 个下降到 10 个的过程中,不会出现流量降级到新加坡,当广州健康副本数低于 10 个后,部分流量将会被负载均衡的新加坡集群:
只要广州主集群的健康度不为 0(v1 副本 > 0), 则第一优先级的广州集群负载流量也会大于 0,保证剩余的可用性尽量满足地域就近负载。
随着 unhealthy 副本数的增加,我们可以看到访问的错误请求数目并未按比例增加,一直保持在一个平稳的错误值,这是因为我们上面给 recommend 服务配置了断路器,因此服务整体的高可用性得以保证。
在更多个集群连通的网格中,负载算法支持多层降级,另外每个地域也可以显示指定流量降级时的下级集群, 各集群的负载权重也可以手动设置。
利用 Istio 和 envoy 的以上能力,结合各集群的资源情况和业务规划,可以让我们调配出高可用、高性能的多集群服务网格。