1. 背景
分布式系统和微服务架构的演进, 使得服务之间开始产生复杂的交互, 系统的能见度越来越弱. 用户看到的一次请求响应, 通常会触发多个系统间的RPC调用和存储操作, 这个现象叫做扇出. 而任何一个子系统的低效都会导致最终的响应缓慢. 我们现存的监控系统能够知道某些用户请求异常或者缓慢, 但是却无法快速定位这个问题是哪个服务造成的. 总结起来主要有这些现象:
-
问题定位难、优化难
-
部门之间踢皮球现象增加
「下单系统好慢, 你查一下是不是你们鉴权服务有问题」
「不是我不想查, 是没法查」
-
异步消息传递不可靠
-
资源浪费严重
任何一次上线都可能引起链路性能的变化, 在快速迭代的系统中, 要求频繁的上线前性能测试几乎不可能.
不能快速定位链路瓶颈, 出现性能问题时, 只能简单粗暴地给整个链路扩容.
-
不能先于用户发现问题后知后觉
「这个bug我得新上个日志, 明天才能分析出来」
-
大量不可重现bug
「刷一下就好了呢」
「我这里是好的哦」
我们公司系统还有一个复杂度就是多语言场景, 这有一定的历史原因. 使用比较广泛的语言是Java, Golang, Node.js 和 Ruby. 我们亟需一个系统能够梳理内部服务之间的关系, 感知上下游服务的形态, 提高系统整体的可观测性, 比如一次请求的流量从哪个服务而来、最终落到了哪个服务中去. 一次分布式请求中的瓶颈节点是哪一个等等.
我们参考了业界的一些分布式跟踪实现, 最终确定基于OpenTracing研发一套支持公司4种语言(Java/Go/Node/Ruby), 双协议(Http/Thrift), 多组件支持(Mysql/Redis/CouchBase等)的全链路跟踪系统 Hunter. 在本篇文章中, 我将简单介绍一下分布式跟踪理论, 以及业界一些优秀的实现. 下一篇文章中将介绍 Hunter 的具体实现.
2. Google Dapper
Google 是最早在大规模分布式系统中实践分布式跟踪的公司之一, Google在2010年发表的论文Dapper, a Large-Scale Distributed Systems Tracing Infrastructure 也成为了其他厂商进行全链路跟踪应用的重要参考文档.
2.1 Dapper 跟踪模型
以下的分布式调用链, 用户请求RequestX直接入口是A系统, 请求引发了其他系统之间的若干次RPC调用.
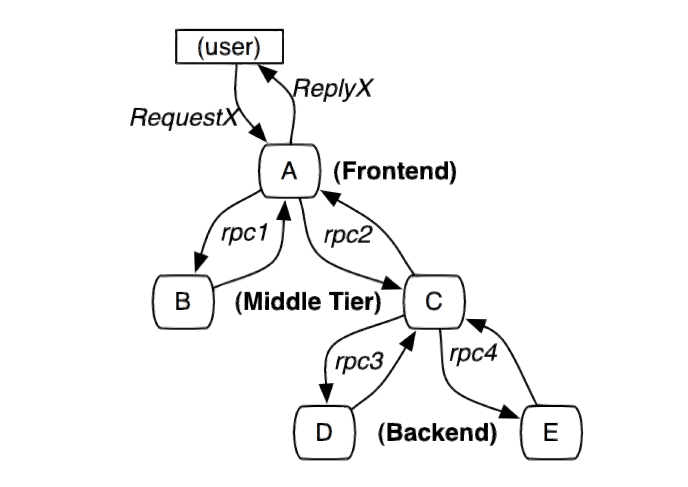
Dapper的核心功能是对每一次RPC的接收和发送设置跟踪标识和其他监控信息(比如耗时等), 并且把这些信息和请求RequestX关联起来. 同时跟踪模型不仅仅局限于特定的RPC框架, 还能跟踪其他行为, 比如SMTP会话, Mysql 操作等等.
2.2 Dapper 数据抽象
Dapper把跟踪模型抽象为Trace Tree 和Span. Trace Tree 代表一次完整的请求调用, Span代表一次RPC调用, Tree的每个节点是对Span的引用, Span之间的连线表示他们的父子关系, 通过parent id来构造, 没有parent id的Span叫做Root Span.
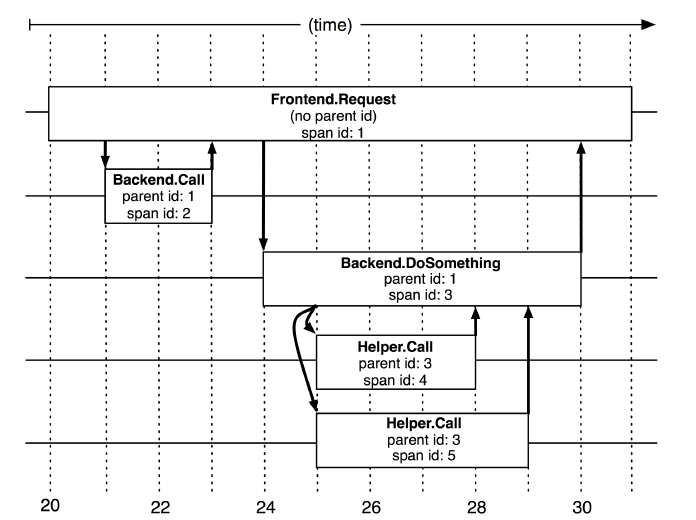
Dapper在RPC收发过程中生成Span, 并把所有Span挂载到特定的Trace Tree上, 这一步可以是异步的.
2.3 Dapper 的其他创新
Dapper设计之初, 参考了一些其他分布式系统的理念比如Magpie和X-Trace, 除了成功地应用了以上跟踪数据模型外, Dapper还有些其他的创新也影响了后续的跟踪系统的发展, 比较重要的有:
-
采样率
低损耗的是Dapper的一个关键的设计目标, 任何给定进程的Dapper的消耗和每个进程单位时间的跟踪的采样率成正比, 想实现低损耗的话, 特别是在高度优化的而且趋于极端延迟敏感的Web服务中,采样率是很必要的.
在较低的采样率和较低的传输负载下可能会导致错过重要事件,而想用较高的采样率就需要能接受的性能损耗, 但即便是1/1000的采样率,对于跟踪数据的通用使用层面上,也可以提供足够多的信息.
如果更智能地, 使用自适应的采样率可以使跟踪系统变得可伸缩,并降低性能损耗.
-
低入侵植入
应用级的透明是跟踪系统推广的关键因素. Dapper对应用的侵入被限制在足够低的水平上, 主要的组件改造技术如下:
- 利用ThreadLocal存储跟踪上下文, 这比较适合多线程的语言平台, 比如Java.
- 对于线程中分化出的延迟调用或者异步调用, 在回调函数触发时, 需要将跟踪上下文和具体线程进行关联.
- Google内部进程间通信框架比较统一, 通过把跟踪信息植入RPC框架, 并使其从客户端传递到服务端以实现链路跟踪.
- 代码植入限制在一小部分公共库的改造上.
低入侵植入的关键在于, 对业务透明地维护跟踪上下文, 维护工作包括创建、存储、获取、以及传递. ThreadLocal是一种常规思路, 对于目前越来越普遍的异步编程和并发编程领域, 比如Node.js和Golang, 都需要特殊的上下文维护方案. 我们将在下一篇文章中分享我们的实现.
3. OpenTracing
对我们的具体系统来说, Dapper更多是分布式跟踪理论的启蒙. 多语言、多RPC协议和多存储, 在全链路跟踪场景下需要一种统一编排API,
当代分布式跟踪系统(例如,Zipkin, Dapper, HTrace, X-Trace等)旨在解决这些问题,但是他们使用不兼容的API来实现各自的应用需求。尽管这些分布式追踪系统有着相似的API语法,但各种语言的开发人员依然很难将他们各自的系统(使用不同的语言和技术)和特定的分布式追踪系统进行整合
OpenTracing通过提供平台无关、厂商无关的API,使得开发人员能够方便的添加(或更换)追踪系统的实现。OpenTracing提供了用于运营支撑系统的和针对特定平台的辅助程序库。
OpenTracing来自大名鼎鼎的CNCF(Cloud Native Computing Foundation), 该基金会的其他著名项目有 kubernetes, Prometheus 等. 随着OpenTracing进入CNCF,这个标准越来越受到开源和商业团队的关注, OpenTracing的标准还在初始阶段, 正在不断改进中.
OpenTracing 延续了Dapper的跟踪模型, 核心对象仍然是基于trace和span, 一个典型的Trace案例如下:
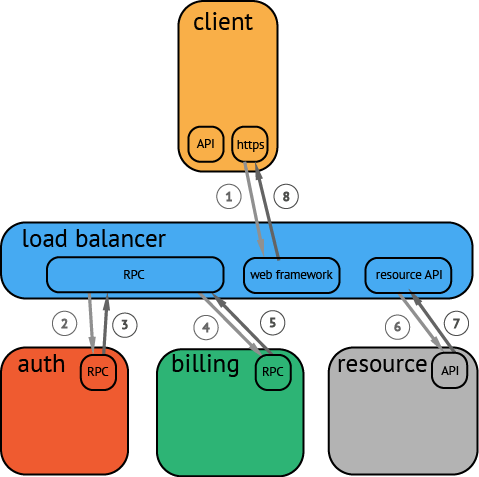
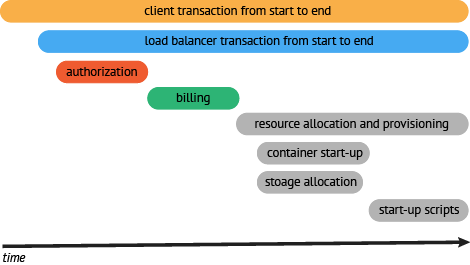
以上调用链路很难说清组件的调用时间,是串行调用还是并行调用,如果展现更复杂的调用关系,会更加复杂. 一种更有效的展现一个典型的trace过程:
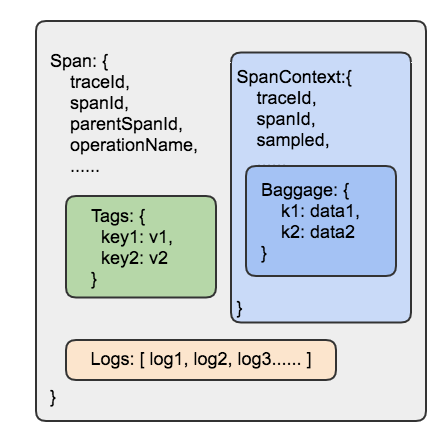
3.1 OpenTracing主要数据模型
-
Trace
代表了一个事务或者流程在(分布式)系统中的执行过程, 是多个span组成的一个有向无环图
-
Span
具有开始时间和执行时长的逻辑运行单元, span之间通过嵌套或者顺序排列建立逻辑因果关系
-
Log
每个span可以进行多次Log操作,每一次Logs操作,都需要一个带时间戳的时间名称,以及可选的任意大小的存储结构.
Log 通常用于记录Span生命周期中发生的事件.
-
Tag
每个span可以有多个键值对(key:value)形式的Tag,Tag是没有时间戳的.
Tag用于记录跟踪系统感兴趣的metric, 不同类型的span可能会记录不同的metric, 比如Http类型的span会记录
http.status_code, mysql 类型span可能使用db.statement来记录执行的sql语句. -
SpanContext
SpanContext代表跨越进程边界,传递到下级span的状态, 至少包含
<trace_id, span_id, sampled>元组, 以及可选的Baggage. SpanContext在整个链路中会向下传递.SpanContext是跨链路传输中非常重要的概念, 它包含了需要在链路中传递的全部信息.
-
Baggage
Baggage通常用于业务数据在全链路数据透明传输.
Baggage是存储在SpanContext中的一个键值对(SpanContext)集合。它会在一条追踪链路上的所有span内全局传输,包含这些span对应的SpanContexts。在这种情况下,”Baggage”会随着trace一同传播,因此得名.
Baggage拥有强大功能,也会有很大的消耗。由于Baggage的全局传输,如果包含的数量量太大,或者元素太多,它将降低系统的吞吐量或增加RPC的延迟。
Span相关数据模型的关系如下:
3.2 平台无关的API语义
OpenTracing 参考并支持了很多不同的平台,每个平台的API试图保持各平台和语言的习惯和管理,尽量做到入乡随俗。每个平台的API,都需要根据核心tracing概念来建模实现。OpenTracing 规定了各语言平台必须实现的接口, 按照OpenTracing的要求进行组件的植入, 就能实现跨语言, 多组件的任意组合. 这和我们目前复杂的系统场景非常契合.

The Tracer Interface
- Start a new Span
- Inject a SpanContext
- Extract a SpanContext
The Span Interface
- Get the Span’s SpanContext
- Finish
- Set a key:value tag on the Span
- Add a new log event
- Set a Baggage item
- Get a Baggage item
The SpanContext Interface
- Iterate over all Baggage items
4. Jaeger
OpenTracing 最重要的意义在于提供了一系列统一的接口规范, 用户需要根据自身系统的需要, 对特定语言的目标跟踪组件进行具体的实现. 我们注意到, Uber工程团队的开源分布式追踪系统Jaeger自2016年起,在公司内部实现了大范围的运用, Jaeger正是基于OpenTracing标准, 同时Uber内部也是多语言系统, 包括Node.js、Python、Go和Java, 这给我们自研全链路跟踪系统树立了很好的榜样.
Jaeger的整体架构如下:
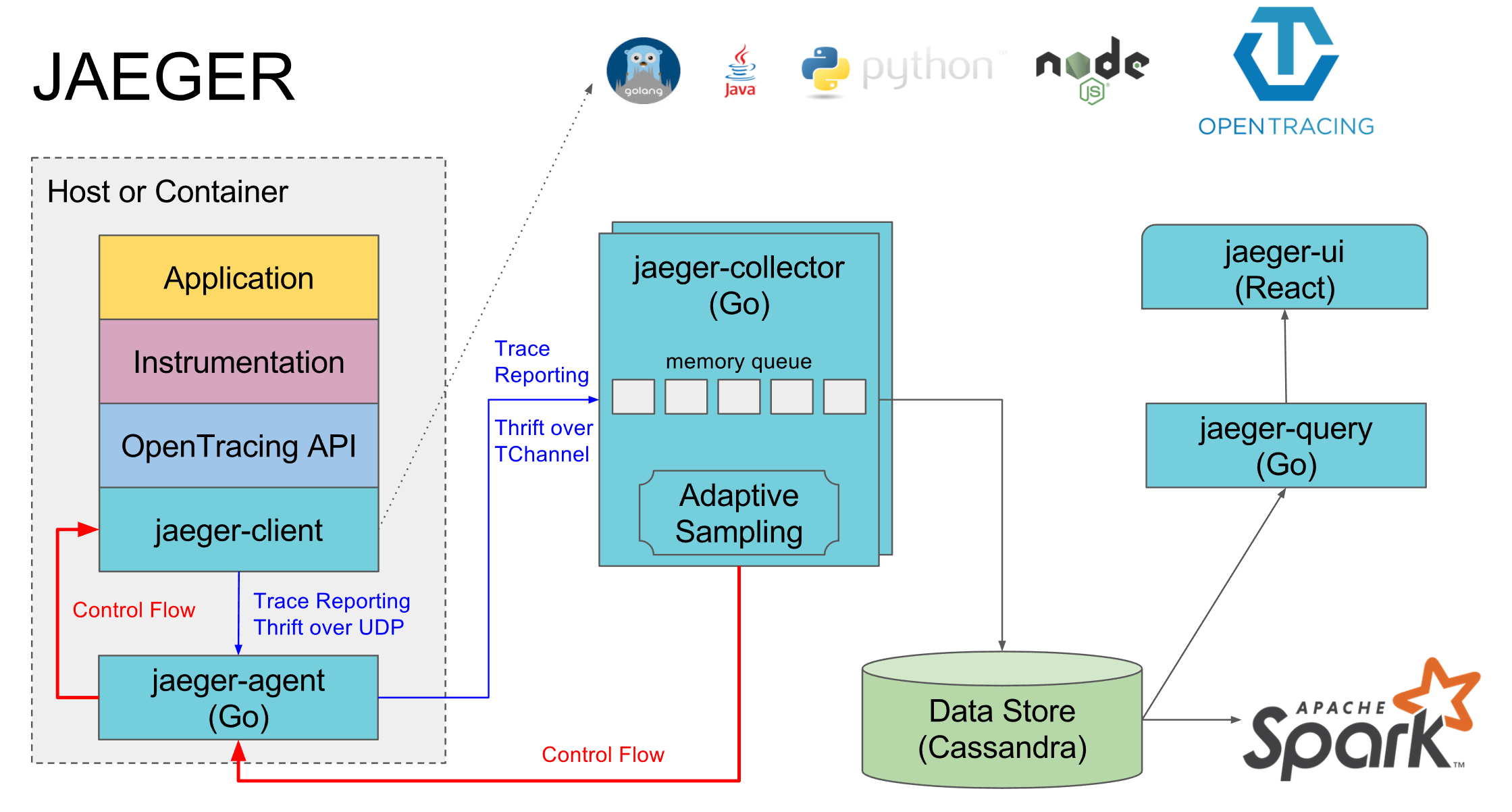
系统中Jaeger Agent, Jaeger Collecor以及Jaeger Qeruy均是使用Go语言实现,客户端库使用了四种支持OpenTracing标准的语言,后端存储使用NoSQL数据库Cassandra, 以及一个基于Apache Spark的后处理和聚合数据管道. 另外还包括一个基于React的Web前端,
其中Agent作为基础架构组件,部署到所有需要度量收集的宿主机上. Agent基于本地回环地址端口创建UDP server, 宿主机器上的目标项目将跟踪span push到Agent, 注意到基于回环地址的UDP报文大小最大约64k, 而跨机器的UDP报文受限于MTU, 报文大小通常小于1500字节. 为了支持多语言的Client 统一Span数据模型, Agent 和Client采用Thrift作为上层RPC协议, 另外Thrift 的二进制序列化格式CompactProtocol/BinaryProtocol足够紧凑. 整体上, 无连接的本机UDP server + Thrift协议非常高效.
Jaeger Collecor 是分布式部署的数据收集后端, 主要用于数据清洗和转存, Agent 和 Collecor 之间使用的是Uber自研的 TChannel协议, 这是一种适用于RPC的网络多路复用和框架协议(受Twiiter Finagle的多路复用RPC协议Mux启发), 可以支持 Thrift 和 HTTP+JSON 等, 该协议的设计目标之一是将分布式追踪能力融入协议中, 为了实现这一目标,TChannel协议规范将追踪字段直接定义到了二进制格式中, 形如:
spanid:8 parentid:8 traceid:8 traceflags:1
各字段含义如下:
| 字段 | 类型 | 描述 |
|---|---|---|
| spanid | int64 | Span 标识 |
| parentid | int64 | 父Span标识 |
| traceid | int64 | 负责分配的原始操作方 |
| traceflags | uint8 | 标志位 |
Tchannel自带的追踪能力是一个重大的飞跃, 可以类比一下HTTP协议中Header的作用. 同时Tchannel发布了多种语言客户端的支持, 加上Tchannel 高效的(Redis-like)网络多路复用功能, 使得该协议在Uber内部得到比较广泛的应用.
Uber公司的多语言分布式追踪系统并非一蹴而就, Jaeger也经历了多次的架构演进, Uber Jaeger 在2017年进行开源, 并在2017年9月加入CNCF基金会, 这将让更多的人了解到分布式全链路跟踪, 特别是在多语言场景下的成功实践.
Jaeger 相关文档:
多语言全链路跟踪系统开发实践: 全链路跟踪系统(二):实践篇