分布式系统
目标
- 提高系统伸缩性
- 提高性能: 分布式意味着可以使用更多的计算机资源, 提高并发能力
- 提高可扩展性
分布式带来的问题
- 服务调用必须走网络
- 分离粒度越小, 服务器越多, 服务宕机的概率也就越大
- 分布式环境中数据一致性和事务难度增大
分布式需要量力而行, 切莫为了分布式而分布式
分布式系统场景
- 分布式应用和服务
- 分布式静态资源 [js css 多个域名, 独立静态资源域名]
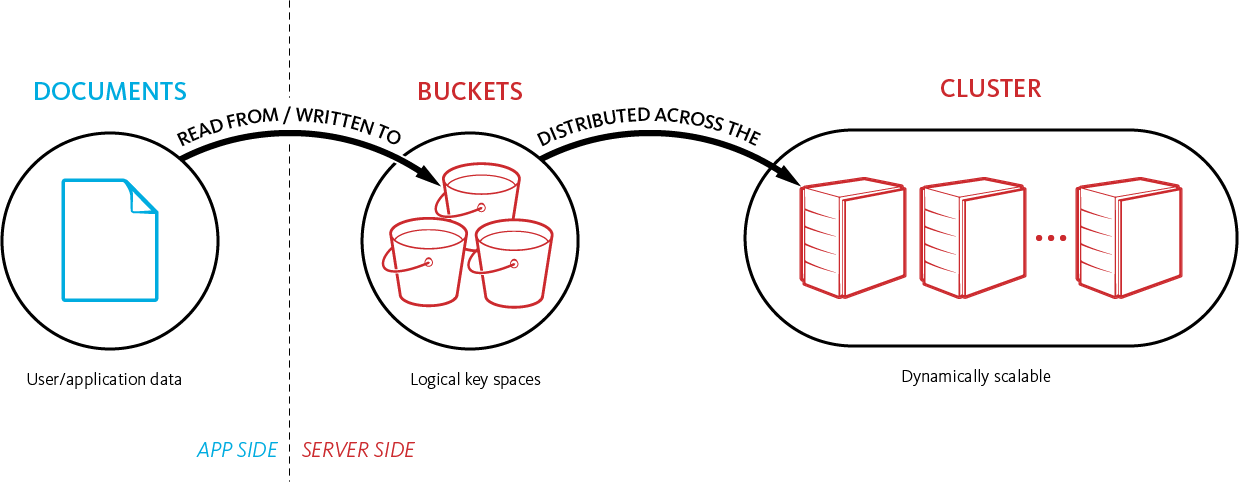
- 分布式数据和存储 [Nosql/分布式文件系统]
- 分布式计算 [deal service 消息分级]
- 分布式配置
- 分布式锁
Why
- 技术选型
- 系统设计
- 资源评估
- 权衡
分布式系统理论
-
异常是常态: 服务器宕机, 网络异常, 磁盘故障
-
请求三态: 成功, 失败, 超时
超时不等同于失败. 超时处理: 不断查询之前操作状态/设计幂等请求
ACID
CAP
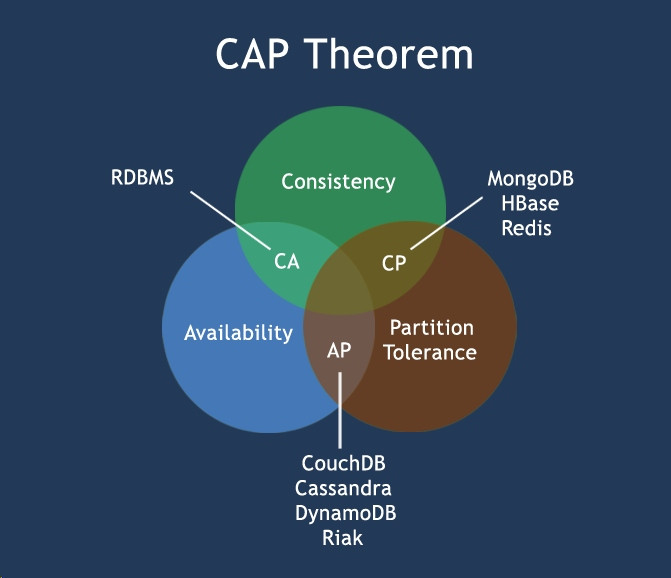
- C 一致性: 数据在多个副本之间是否能够保持一致的特性
- A 可用性: 在任何时刻对大规模的数据读写操作都能保证在限定的延时内返回合理结果
- P 分区容忍性: 当部分节点无法互通出现网络分区现象,但是整个系统还是可以对外提供服务
BASE
- 基本可用(Basically Available)
- 软状态( Soft State)
- 最终一致性( Eventual Consistency)
一致性协议
- 两阶段提交
- 三阶段提交
- 向量时钟
- RWN协议
- Paxos协议
- Raft协议
术语
-
机器节点(Node)
-
Rebalance: online-rebalancing/auto-sharding
-
分区容错(Partition Tolerance)
-
逻辑分区: key空间/Bucket/Index/Topic
-
数据分片(Partition): Slot/vBuckets/Shard/Partition
-
数据路由(Routing):
-
哈希分片(Hash Partition) :
1) 哈希取模(Round Robin):
H(key)=hash(key) mod lengthOfNode: 未区分node和Partition角色, Node增删将导致hash不稳定2) 虚拟桶(Virtual Buckets):
Key->PartitionPartition->Node3) 一致性哈希(Consistent Hashing):
-
范围分片(Range Partition)
-
-
复制(Replication): 按照复制粒度, 可分为节点复制和分片复制
-
复制策略: 常见的是同步和异步, 异步可以有多种权衡策略
-
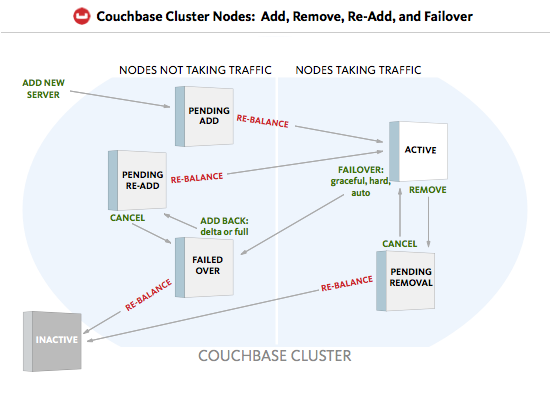
失效转移(Failover)
-
读扩展
-
向量时钟, WNR
-
事务
-
乐观锁
-
悲观锁
-
持久化(Durability)
概念
一致性哈希
要解决的问题:
- 散列的不变性
- 异常以后的分散性
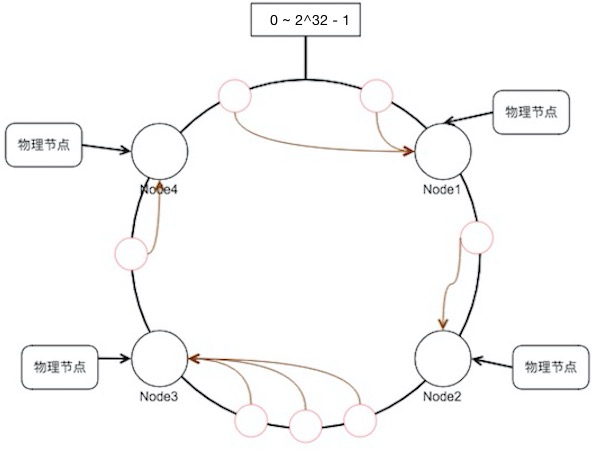
问题:
- 新加入一个节点后, 新节点和分离节点的负载是其他节点的一半, 负载不均衡
- 性能高和性能低的机器, 负载需要不同
改进: 引入虚拟层, 虚拟节点
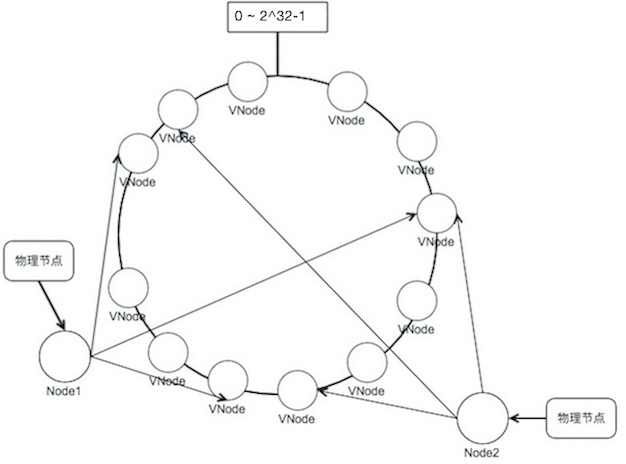
稳定性分析: N 个node的集群, 新增一个node, 数据继续命中原node的概率
- 哈希取模: 1/(N+1)
- 一致性哈希: N/(N+1)
向量时钟
使用向量时钟的Nosql: Dynamo, Riak
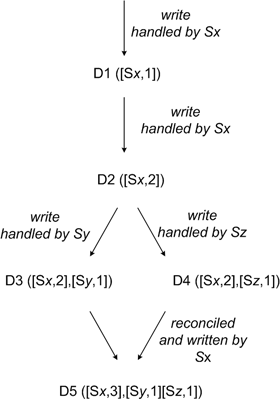
- R 一次成功读操作中最少参与的节点数目
- W 一次成功写操作中最少参与的节点数目
- N 节点数目
当W+R > N,写成功需要的副本数 + 读成功需要的副本数 > 副本总数,则能保证最终一致性.
并发情况下的写丢失
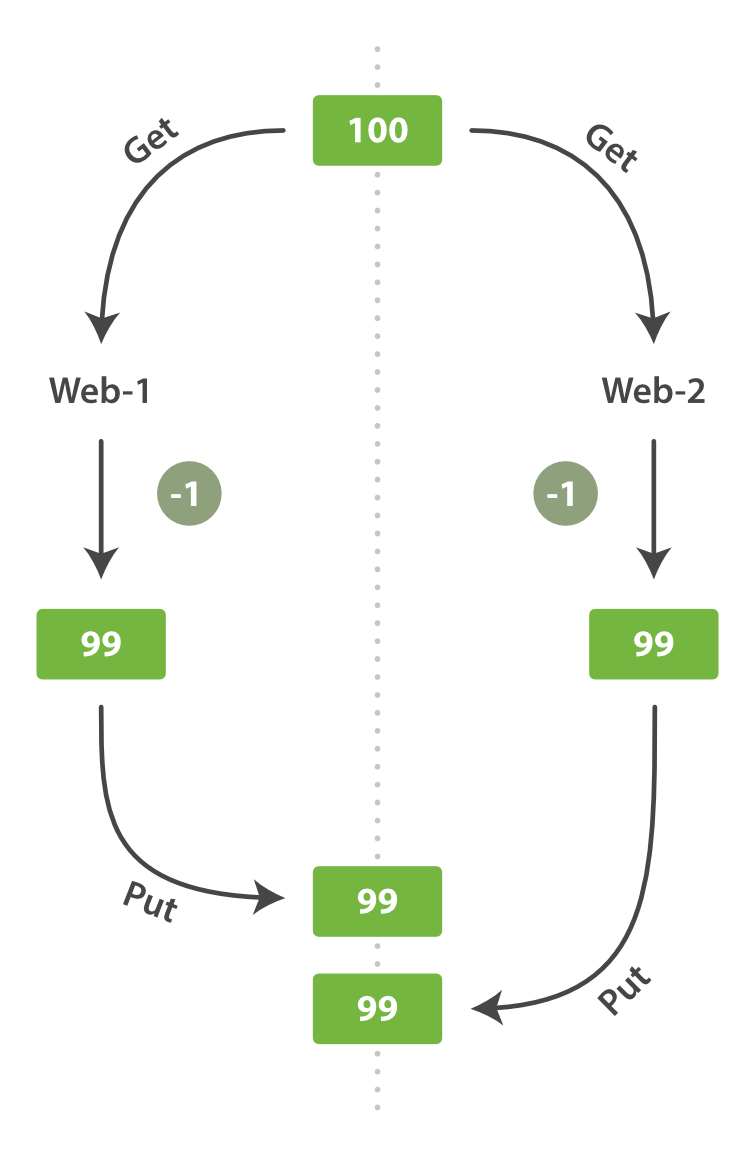
解决方案:
- 悲观锁
- 乐观锁
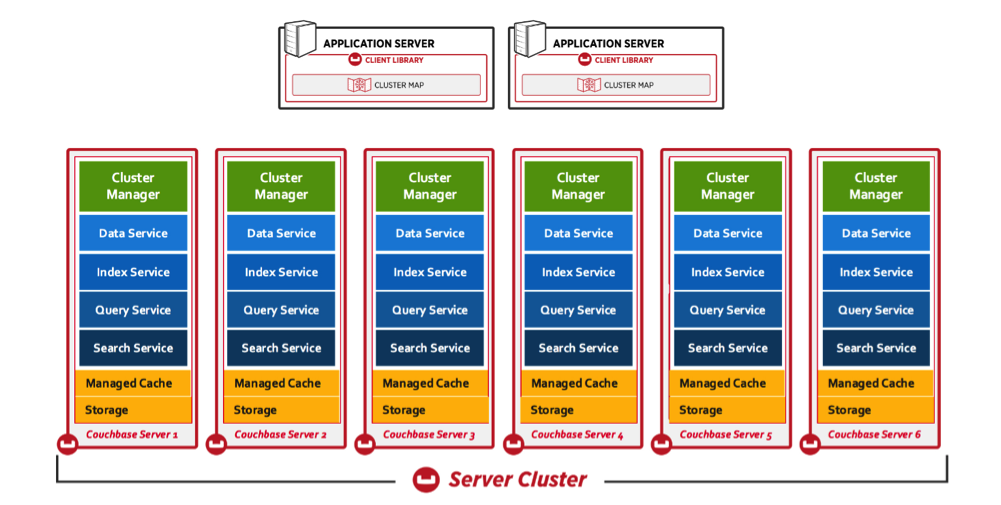
CouchBase
集群结构
分片
复制
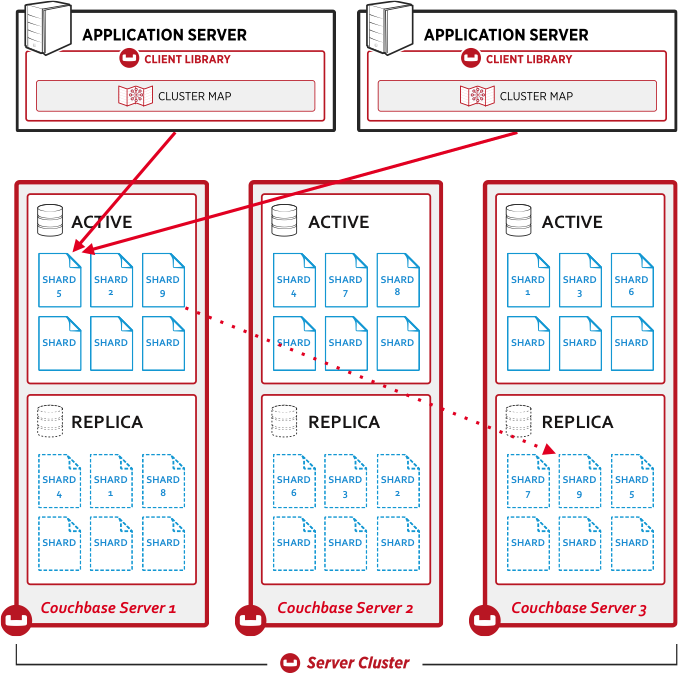
Rebalance
Elasticsearch
Node, 分片, 复制
Auto Sharding
失效转移
Client-Node 交互
协调node转发
mget:
副本同步/写安全/复制策略(sync)
协调node转发+同步复制(同步的目标是修改后的完整文档, 而不是修改操作)
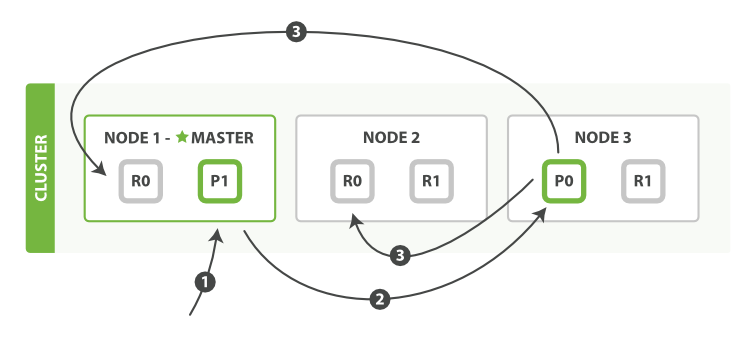
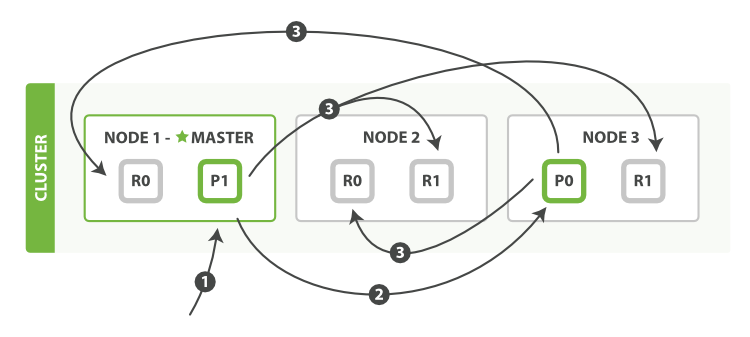
批量写:
以下是几种分布式系统的比较:
描述 | CAP | Redis (Cluster) | CouchBase | ES | Kafka | |
|---|---|---|---|---|---|---|
API | ||||||
| CAP | 长时间(A)提供高吞吐量的(P)正确(C)读写服务 |
| Redis主从/哨兵: CP Redis Cluster: AP | CP: 复制数据默认不提供服务 (可用性A降低) replica仅作为高可用, 默认不提供读 (一致性C高) | https://discuss.elastic.co/t/elasticsearch-and-the-cap-theorem/15102 | |
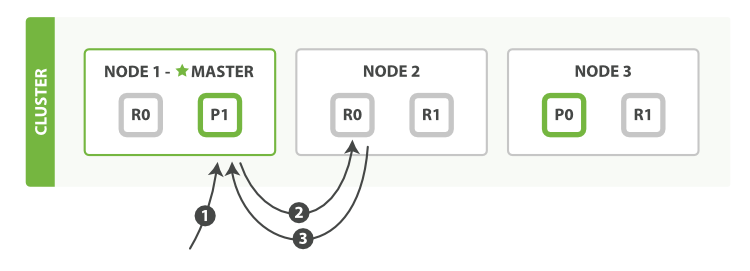
| Client-Node 交互 | 1) 直连: 通常client持有Routing Map 延迟低 2) 代理: 延迟高
| 直连, 无代理 Smart Client(client-side key hash) node 重定向: ASK/MOVE, 对client不透明 | 直连, 无代理 Smart Client(client-side key hash) | 协调者转发, 对client透明 任何阶段都可以响应任何client请求 node(协调节点)计算routing后转发到相应node, 数据返回协调者后, 协调者再返回client 写:受Majority Quorum限制 读:协调者轮询有数据的分片
client建议是轮询node(作为协调节点) | TODO | |
| client和集群间 | 基于主键 集群节点不代理其他节点, 而是指导client进行跳转找到正确的node (moved, asked) 异步复制, 节点写入不等待其他节点确认, 直接返回客户端(除非明确要求WAIT)
|
没有用于CURD 的 restful API, 有用于管理的http api | 1) RESTful API: 默认端口9200 2) java 2中客户端: 默认端口9300, 协议: Elasticsearch Transport Protocol 1) node client: 以无数据节点(none data node)身份加入集群,换言之,它自己不存储任何数据,但是它知道数据在集群中的具体位置,并且能够直接转发请求到对应的节点上 2) Transport client: 不加入集群,只是简单转发请求给集群中的节点
| |||
| CURD | Insert Upsert Replace Get Remove | 查询: GET /{index}/{type}/{id} 新建: PUT /{index}/{type}/{id} (文档不存在) 全量更新: PUT /{index}/{type}/{id} (文档存在) 局部更新: POST /{index}/{type}/{id}/_update 删除: DELETE /{index}/{type}/{id}
upsert: 更新或新建 | ||||
Node
| 通常是指独立的服务器或者独立的进程 | 水平伸缩性 | 对等节点 节点属性: 节点ID(初次启动获得, 存于配置文件)
| 对等节点(peer-to-peer node) 所有节点类型和结构相同, 不过会选择一个orchestrator Node提供的服务(可配置node部分开启, MDS): Cluster manager Data service: KV CRUD Index service Query service:N1QL
| 对等节点(peer-to-peer node) 集群选举一个主节点: 负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等
| Broker 其中一个Broker会被选举为Controller,主要负责Partition管理和副本状态管理,也会执行类似于重分配Partition之类的管理任务 |
Node 伸缩 (Rebalance/ Reshard) | 实际操作: 增删node时, 需要迁移数据 2个原因: 1) 需要扩容 2) node 失效 分片(Partition)是Rebalance迁移的目标
| P | 最多16384个node online rebalancing 支持(手动)在线reshard, 把哈希槽从一个节点移到另一个节点
| online rebalancing, 无需服务停机 auto-sharding
以 vBucket 为单位的主从备份, 可以方便灵活的把数据的子集在不同节点上移动,以实现集群动态管理
| online rebalancing, 无需服务停机 auto-sharding: 自动检测和删除失败的节点,并重新组织集群 | |
| node间 | node在cluster bus上使用 gossip 协议来发布广播消息,通知配置变更 Redis 集群是一个网状结构,每个节点都通过 TCP 连接跟其他每个节点连接 每个节点都有 N-1 个流出的 TCP 连接,和 N-1 个流入的连接。 这些 TCP 连接会永久保持 | DCP | gossip 协议 (单播时?) 端口9300 | |||
| Sub-Document | 支持原子性 https://developer.couchbase.com/documentation/server/4.6/sdk/subdocument-operations.html 读: LookupIn: (可能部分成功)写: MutateIn: (原子操作, 如果有有任何path失败, 全量回滚) | 支持文档部分更新, 内部: 检索-修改-重建索引 | ||||
| value数值增减 | 原子操作 | incr incrby incrbyfloat | counter 原子操作, 无法指定cas | N/A | ||
| web管理 | 监控工具: TODO | 自带webconsole | Sense, Marvel, elasticsearch-head | yahoo/kafka-manager | ||
| 乐观锁 | Compare And Swap CAS是乐观锁的一种形式 代表数据当前状态 guideline: 1)检索 和 重建索引 步骤的间隔越小,变更冲突的机会越小 2)冲突后通常方案是重新获取并重试
| C | WATCH key [key ...] 需要结合事务 | 支持 每次文档访问时作为metadata信息返回 在执行修改操作时可以作为参数传递到server | 文档更新时, _version递增 在修改文档时, 传递version实现乐观锁控制 除了默认的_version, 还支持使用外部系统版本号作为乐观锁 支持参数: retry_on_conflict=N 自动重试N次
| broker是无状态的, 它不需要标记哪些消息被哪些consumer过,不需要通过broker去保证同一个consumer group只有一个consumer能消费某一条消息,因此也就不需要锁机制 |
| 事务 | C | 单机支持, 满足原子性执行, 但不支持回滚 MULTI 开启事务 ...... EXEC 执行事务 WATCH key [key ...] 乐观锁可以实现中断事务 | 无 | 不支持ACID事务 | ||
| 以下内容未完成 | 以下内容未完成 | |||||
| 伸缩操作 | 增加节点: 手动meet, 缺乏自动发现 redis-trib.rb add-node redis-trib.rb reshard | |||||
| 健康检查 | 1)集群健康检查 GET /_cluster/health GET _cluster/health?level=indices GET _cluster/health?level=shards status:
2)node统计 GET _nodes/stats 3) 集群统计 GET _cluster/stats 4)索引统计GET my_index,another_index/_stats | |||||
| 内容数值增减 | hash: hincrby, hincrbyfloat zset: zincrby
| sub操作 | ||||
分区容错 (Partition Tolerance) | 当出现网络分区(脑裂)时系统也可以继续工作 | P | 仅能容忍集群中少数节点的出错 脑裂分区可用条件: 多数master存活+其他master有存活的slave, NODE_TIMEOUT后从提升为主 | node fail时, 该node的数据无法写, 在足够vBucket的分区中, 失效转移完成后集群恢复. | discovery.zen.minimum_master_nodes: 用于控制脑裂后的可用集群, 通常设置原则是(master_eligible_nodes / 2)+ 1 网络分区后, 集群中索引状态, 取决于该分区中是否有完整的分区(primary或者replica都行), 如果不满足, 该索引状态标红.
如果某个分片primary和replica都失效, 集群仍然可以提供其他分片查询. | |
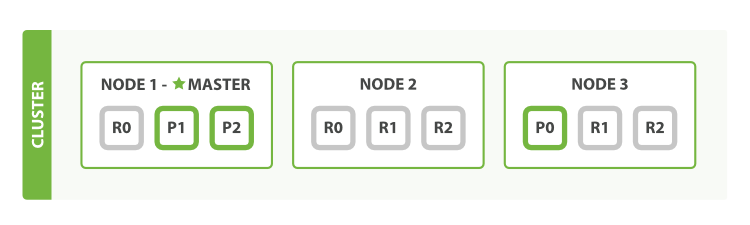
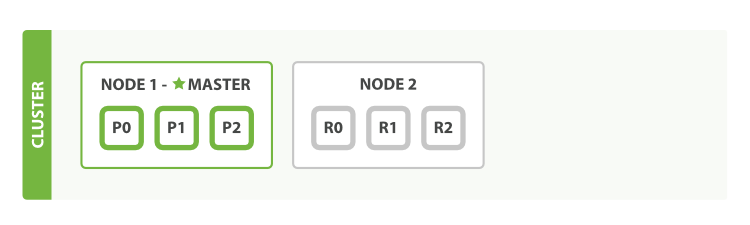
分片 (Partition/Shard) | 作用:水平扩展(将负载能力提升为 `单机能力*N`) 同时提升读写能力
复制和分片是正交的 | 降低A | Slot 角色: 分片无差别, 关键在于node的角色 每个Cluster分为16384个slot | vBuckets 1024 个vBuckets
| Shard(分片): 本身是一个 Lucene 的实例 主分片数在index创建时固定 副本分片数量可以随时调整 | Partition 消息在一个Partition中的顺序是有序的,但是Kafka只保证消息在一个Partition中有序,如果要想使整个topic中的消息有序,那么一个topic仅设置一个Partition即可 Partition是最小并发粒度(对应consumer) |
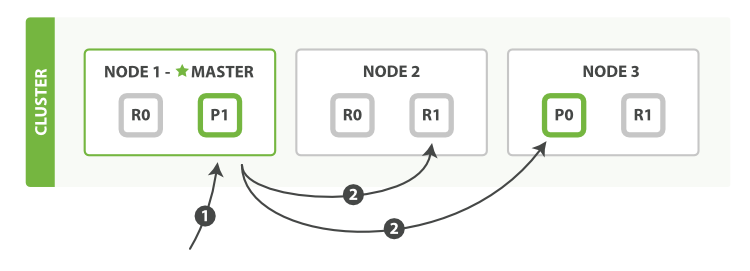
| 副本同步/写安全/复制策略(sync) | 某些场景可以叫做主从同步 分为: 1) 多写/双主: 如果不使用一致性协议, 更新顺序无法保证, 数据会出现不一致 2) 同步主从更新: 强一致性, 高延迟 3) 异步主从更新: 请求延迟和一致性之前的权衡, 常见权衡策略: Majority Quorum, WNR, ISR 4) 任意节点更新 TODO
| A, C以及延迟的权衡 | 存在写丢失的可能, 原因: 1) 默认异步复制 (好处是速度快) 2) last failover wins(最后选举出的master数据最终替换其它副本) 示例: 1) 主写入, 响应client, 但是在同步给从之前挂掉了, 从提升为主, 造成写丢失 2) 主挂掉, 从提升, 有的客户端还没来得及更新路由, 这时候原来的主复活, 但是还没来得及降为从, 此时接收到写 3) 一个master不可达, 达到`NODE_TIMEOUT` 将发生故障转移, 但是如果在`NODE_TIMEOUT`之前, 网络分区修复了, 就不会有写丢失, 但是如果网络分区超过`NODE_TIMEOUT`, 应用在少数派的写将丢失. 在这之后, 少数派将拒接写入. 这是为什么redis只能拿来做缓存 | 默认索引和复制都是异步更新 | 默认情况同步更新副本, 强一致性.
Majority Quorum 默认情况, 当number_of_replicas>1, 主分片需要大多数分片写入成功: int( (primary + number_of_replicas) / 2 ) + 1 number_of_replicas是Index指定的副本数量 满足以上条件后, es的复制策略是同步更新,写安全 同步的目标是修改后的完整文档, 而不是修改操作 | follower从leader pull数据, Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中, leader收到所有ISR的ACK后, 标记log为commit, Leader将增加HW(High Watermark)并且向Producer发送ACK??? (性能和数据持久化上做了一个比较好的平衡) 只有被commit过的消息(offset低于HW的消息)才会暴露给Consumer 如果replica.lag.time.max.ms 内 follower没有fetch leader, leader将把该follower从Isr中移除
Producers:采用异步push方式, 可以通过参数控制是采用同步还是异步方式 producer端参数控制: acks=0: producer不需要leader发送响应,即producer只管发不管发送成功与否, 延迟低,容易丢失数据 acks=1:表示leader写入成功(但是并没有刷新到磁盘)后即向producer响应。延迟中等,一旦leader副本挂了,就会丢失数据 acks=-1/all:表示leader会等待isr列表中所有副本都写入成功才向producer发送响应。延迟高、可靠性高。但是也会丢数据. |
| 副本同步权衡 | C | 支持同步复制: WAIT numslaves timeout | API可以调整 replicateTo和persistTo来控制同步复制数据 | 默认: Majority Quorum+ 同步更新 异步: 可以在写url上加上参数?replication=async 实现异步 (但是2.0后移除了) 异步: 配置项consistent, 同步成功副本数量, 默认是int( (primary + number_of_replicas) / 2 ) + 1 | 配置中min.insync.replicas (默认1) 当acks=-1时, leader写入时, 如果size(isr) < min.insync.replicas, 则默认不写入 | |
| 原子性 | 文档级别原子性, 所有KV操作都是原子操作
| 文档级别的变更支持 ACID | ||||
| 和关系型数据库比较 | Database | 单机版0~15, 默认0号Database, Cluster只能使用0号db | Bucket | Index | N/A | |
复制/副本 (Replication) | 冗余的一种方式, 提高可用性, 实现容灾(disaster recovery) 有复制, 才能在必要时进行Failover
为什么需要分角色: 一致性问题 主写: 1*N的数据同步 全写: N*N的数据同步 | 提升A 使得一致性更难达成. | 对node进行复制 角色: master node, slave node 一主多从 复制数量为1, 2个node fail时, 集群存活概率:1-(1/(N*2-1)) | 对分片(vBuckets)进行复制 角色: 每个 Bucket 包含 1024 active vBuckets, 1024 replica 最多支持3个复制, 也就是4份数据 TODO node 挂了以后, 集群存活概率 | 对分片(shard)进行复制 角色:primary shard(主分片), replica shard(副本分片) | 对分片(Partition)进行复制 角色: leader, follower, Isr Isr: in-sync, 当前活跃的副本列表, 是Replicas的子集 |
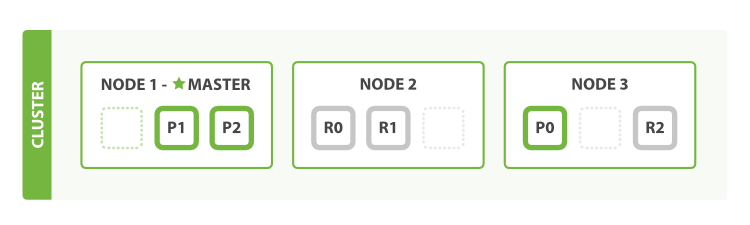
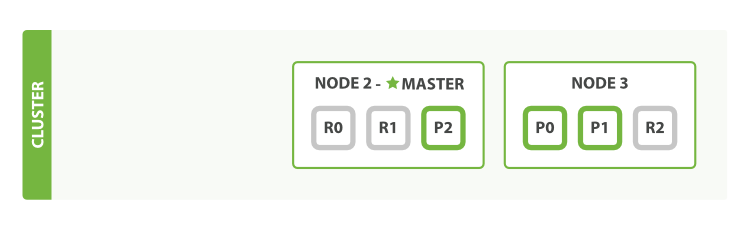
失效转移 (Failover) | 副本的角色提升, 通常发送在Node失效的情况下 | A | 失效的master node对应的slave提升为master (自动) | 支持自动/手动 找到失效节点中的原active vBuckets对应的replica vBuckets, 设为active | 自动 找到失效node中原primary shard对应的replica, 提升为primary. | 当broker失效, 对于该broker上的分片: 从followers中选举leader |
| 悲观锁 | C | 不支持 | 支持, 但不常用 | 支持(不常用, 挺复杂): 全局锁 文档锁 树锁 | N/A | |
| 批量操作 | 节约网络开销, 通常是非原子性 存在部分成功部分失败 | multiple 操作: 满足原子性. 如mget, mset, hmget,hmset pipeline: 非事务性, guideline: 不要过大 cluster 不支持不同分片的pipeline, 需要客户端自行实现分组 | SDK 并行分组发送 非事务性 guideline: 1M 数据结构: gocb.BulkOp, gocb.*Op 执行: bucket.Do | 1) 批量获取: GET /_mget 2) bulk API: 可以混合create 、 index 、 update 或 delete guideline: 最佳值不是一个固定的值, 建议基准测试 | Producers: Kafka支持以消息集合为单位进行批量发送 | |
| 持久化(Durability) | A | 可选: 1) Snapshot: 数据可能缺失部分; copy-on-write造成极端情况内存是实际数据的2倍; db文件尺寸小; 恢复快 | https://developer.couchbase.com/documentation/server/4.6/sdk/durability.html 持久化和复制是异步进行(可以通过SDK参数控制) 持久化和复制是可能丢失的: node fail时, disk queue 和 replication queue会丢失 这是为什么可用性不高 | 文档被索引->文档加入内存缓存区, 并追加到translog->定期refresh
| 每个分区在物理上对应一个文件夹,以`topicName_partitionIndex`的命名方式命名,该文件夹下存储这个分区的所有消息(.log)和索引文件(.index) 顺序写磁盘 | |
| 持久化/复制 | *Dura 参数: replicateTo: 复制数量, 最大值是复制集数量 persistTo: 持久化到硬盘数量,最大值是复制集数量+1, 如果是1表示active node | |||||
数据模型 | ||||||
| 数据类型/模型 | string map set hash list sortedset(zset) | KV Document 另外语言SDK中提供若干api支持基于document的数据类型: Data Structures Map List Queue(FIFO) Set | 文档元数据: _index: 文档所属索引 _type: 文档类型 _id: 文档id, 和_index, _type组合可以唯一确定一个文档 _version: 用于实现乐观锁 文档不能被修改, 只能被替换 | TODO 消息结构 | ||
数据路由 (Routing) | 数据分片后, 数据到node的映射 通常是两层映射关系: key->分片 分片->node |
分片数量固定且不能调整 | Smart Client: 同步 vBucket 表, 在客户端实现负载均衡, 高效应对节点失效 Map在node和client都存在(Client Topology Awareness) Cluster Map : services 和node的映射, 包括vBucket map vBucket map: vBucket和node的映射 映射函数: func(documentID) -> vBucketID 分片数量不固定, 可调整 | 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点. shard = hash(routing) % number_of_primary_shards 其中routing默认是文档_id, 也可以自定义 分片数量不固定, (初始化后)不能调整 是否限制了分片的扩展性: 可以多加index来实现分片扩展 | Producer:可以自己决定把消息发布到这个主题的哪个Partition Consumer: N/A
TODO:
分片数量不固定(配置num.partitions), 可调整 (TODO) | |
术语 | ||||||
特征 | ||||||
| 特点 | Cluster: 1) 高性能和线性可扩展性: 最多可达1000个node, 无代理, 异步复制 多数master存活+其他master有存活的slave replicas migration: slave 借用 | 可扩展的数据模型 1) 高可用 2) 可扩展 3) 高性能 4) 安全性 5) 多种的数据交互方式 | 1) 分布式的实时文件存储,每个字段都被索引并可被搜索 | |||
| 类型 | 内存型 KV Nosql | 内存型 Nosql, 同时支持KV和文档 文档可以认为是KV类型的V, 文档有独立于V的K, 也就是id) | 实时的分布式搜索分析引擎 文档型 | 消息系统 | ||
维护 | ||||||
| 维护 | 支持在线部署, 包括升级, 伸缩(增删node), 失效转移, 监控, 压缩备份等 | |||||
网络协议与交互 |
| https://developer.couchbase.com/documentation/server/4.6/architecture/connectivity-architecture.html | ||||
| 自动发现 | 不能自动节点发现, 需要手动meet | 支持 两种组网方式: 1) multicast: 组播 2) unicast: 单播, 需要配置单播节点, 通常配master(作为gossip router) | ||||
| 自增id | 不支持, 需要客户端提供key | 不支持, 需要客户端提供key(id) | _id可以客户端提供, 也可以自动生成 | |||
| 读从/复制node(读写分离) | GetReplica 数据可能不一致 仅用于active node 不可用 | |||||
| 读扩展 | 复制产生主从, 不同集群从的角色不一. 有的仅作为backup来支持Failover 有的从可以支持读, 以实现主从分离. | slave默认不提供读, 只作为备份 READONLY 选项可以水平扩展读, 其实作用有限. 利用slave扩展读可以自行在client端实现(要能忍受脏数据) | 复制分片默认不可读, 只是为高可用, 这样的好处是利于实现数据一致性.(读写同时在active分片) As of Couchbase Server 2.1.0, we have a binary protocol to retrieve replicated data for a given key(客户端要能容忍数据不一致) | 复制分片可以提供读和搜索 | leader负责读写, followers 仅作为backup (没有必要读扩展) | |
| 过期时间 | 1) 惰性过期: 操作指定key时, 检测过期时间, 如果已过期则删除 | 支持 | 支持
注: 大多数操作会隐式去掉过期时间, 因此需要在所有写入(mutation)操作中带上过期时间 | 不支持 某些场景下可以按照时间范围创建索引. 需要删除时直接删除整个索引. | 基于时间删除: 配置log.retention.hours 基于partition文件大小删除: log.segment.bytes | |
| 过期时间 | GetAndTouch Touch | |||||
| 逻辑空间 | 一个redis Cluster 是一个逻辑key空间 | Bucket 一个集群可以有多个逻辑空间(Bucket) 隔离以下实体: key空间 cache, io管理 鉴权 XDCR 索引, 视图 | Index: 实际上是指向一个或者多个物理 分片 的 逻辑命名空间 一个集群可以有多个逻辑空间(Index) es 支持操作多索引, 多索引(多租户技术)是扩容的一种方案(因为主分片无法扩容) | Topic 一个集群可以有多个逻辑空间(Topic) | ||
| 集群搭建 | redis-trib.rb create --replicas | 集群是由一个或者多个拥有相同 cluster.name 配置的节点组成 | ||||
| Table | N/A | Bucket or Item (with type designator attribute) | Type | N/A | ||
| Row | N/A | Item (key-value or document) | Document | N/A | ||
| Column | N/A | Document Field | Field | N/A | ||
| Index | N/A | Index
| 倒排索引(默认的,一个文档中的每一个属性都是 被索引 的) | N/A | ||
| ||||||
| consistency 参数 TODO | 读取特定消息的时间复杂度为O(1)
| |||||