1. TOKENIZATION AND PARSING
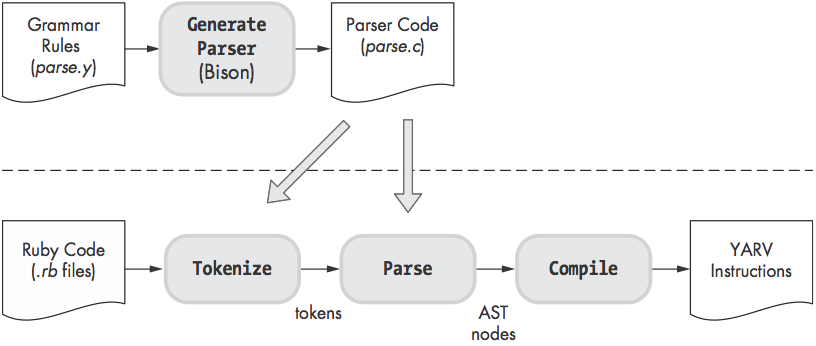
- 执行代码前三个遍历: Tokenize, Parse, Compile
Tokenize


- Tokens: The Words That Make Up the Ruby Language
tINTEGER数字字面量tIDENTIFIER非保留字, 可用作变量名, 方法名, 类名keyword_do保留ruby关键字, 不可以作为普通变量名, 但还是可以作为 method names, global variable names, instance variable names-
使用Ripper观察TOKENIZATION
require 'ripper' require 'pp' code = <<STR 10.times do |n| puts n end STR puts code pp Ripper.lex(code)
Parsing
- Ruby 使用的parser generator 叫做Bison, Yacc (Yet Another Compiler Compiler)的早期版本
- Bison接收一系列语法规则(定义在parse.y, ruby语言的核心), 生成 parser (parse.c), 然后parser再去parse token.
- parse.y和生成的parse.c 也包含Tokenize的功能代码
- Tokenize 和 Parse 其实是同时进行
- LALR(Look-Ahead Left Reversed Rightmost)
- L(left) 从左到右parse token
-
R (reversed rightmost derivation) 反向最右推导?? 采用shift/reduce
shift 到 Grammar Rule Stack, reduce 为一个Grammar Rule
- LA(look ahead) the parser looks ahead at the next token, the parser maintains a state table of possible outcomes depending on what the next token is and which grammar rule was just parsed.
-y参数可以展示parse过程, 如ruby -y simple.rb-
用Ripper查看解析过程
require 'ripper' require 'pp' code = <<STR 10.times do |n| puts n end STR puts code pp Ripper.sexp(code) - 解析结果是abstract syntax tree (AST)
2. COMPILATION
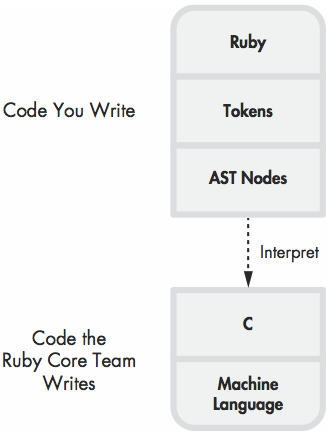
- ruby 1.8 没有编译过程, ruby team编写的C代码, 直接解释运行parser生成的AST

- compile means to translate your code from one programming language to another (ruby代码 -> YARV指令)
- YARV : Yet Another Ruby Virtual Machine
-
you don’t use Ruby’s compiler directly; unlike in C or Java, Ruby’s compiler runs automatically without you ever knowing
-
YARV: It’s a stack-oriented virtual machine. That means when YARV executes your code, it maintains a stack of values—mainly arguments and return values for the YARV instructions
-
AST节点:
NODE_SCOPE: 作用域, 包含因子: table(输入变量名?) args(输入变量个数?)NODE_FCALL函数调用的NODE_CALL代表方法调用NODE_ITER: literal stringNODE_DVAR: block parameterNODE_LIT:
-
NODE_FCALLNODE_CALL都会被编译为以下YARV指令:- Push receiver
- Push arguments
- Call the method/function
- Ruby 的 parser, compiler 区分函数和方法: 方法调用有明确的 receiver, 函数调用的receiver是当前self
- Compiler通过变量AST就能获得正确的指令执行顺序
-
puts 2+2生成的YARV指令YARV instructions putself putobject 2 putobject 2 send <callinfo!mid:+, argc:1, ... #将被优化为opt_plus send <callinfo!mid:puts, argc:1, ... - (methods, blocks, classes, modules) Each
NODE_SCOPEis compiled into a new snippet of YARV instructions -
观察YARV指令:
code = <<END puts 2+2 END puts RubyVM::InstructionSequence.compile(code).disasm

-
local tablecompiler将会从AST中复制出block参数到local table, 每一个scope有自己的local table用于存储局部变量和block参数
-
各参数标签
-
标准的方法参数或者block参数 -
使用`*`的数组参数 -
数组参数后面的标准参数 -
使用`&`表示的block参数 - <Opt=i> 带有默认值的参数,
i表示默认值存储的下标
-
3. HOW RUBY EXECUTES YOUR CODE
TODO
4. CONTROL STRUCTURES AND METHOD DISPATCH
TODO
5. OBJECTS AND CLASSES
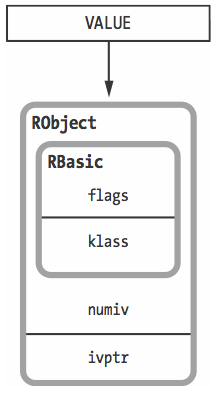
RObject
Every Ruby object is the combination of a class pointer and an array of instance variables.
所有ruby对象都是: 包含一个指向其class的指针, 以及一个存储实例变量的数组的集合
-
Ruby always refers to any value with a VALUE pointer, VALUE 是一个指针类型
对象inspect结果如
#<Mathematician:0x007fbd738608c0>16进制数组表示VALUE指针地址, 每个对象不相同 - klass: 所属类的指针
- numiv: 实例变量个数
- ivptr: 实例变量数组的指针
iv_index_tbl: 指向Rclass中的存储实例变量的映射关系, 是一个hash table, 用于解释ivptr内容
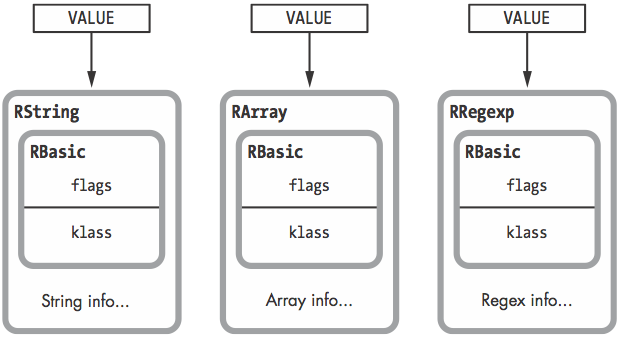
- custom对象使用RObject, ruby内置对象叫做
generic objects, 不使用RObject:- string: RString
- array: RArray
- 正则: RRegexp
但所有类型对象都使用RBasic结构
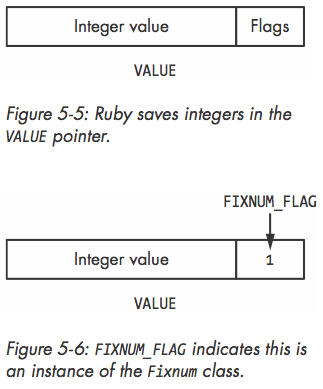
- 简单值(integer, symbol, nil, true, false)没有对象结构, 直接存于VALUE
- These VALUEs are not pointers at all; they’re values themselves
- 无klass指针, 在flag中复制出标明klass标志位
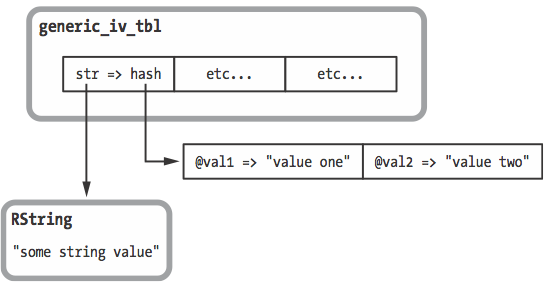
- 对不使用RObject结构的对象, 实例变量都存在hash
generic_iv_tbl中
- ivptr 在ruby1.8里是hash, 存储实例变量的名称内容, 1.9 以及上改为了数组, 单纯存储实例变量值
- ruby1.9及以上, ivptr 第一次分配7个, 当添加第8个时, ruby再分配3个, 这能说明为什么添加实例变量耗时的变化
RClass
A Ruby class is a Ruby object that also contains method definitions, attribute names, a superclass pointer, and a constants table
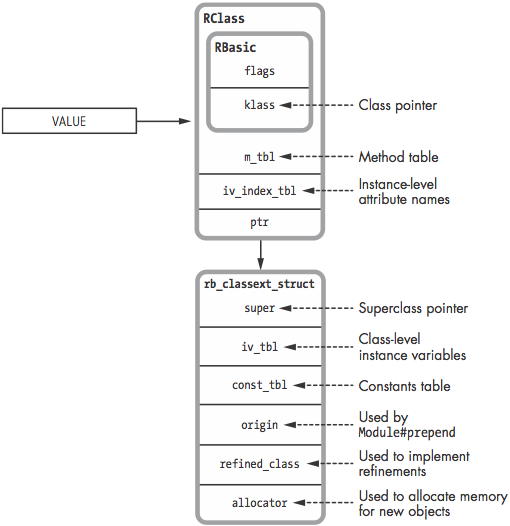
klass pointer指向Class, 用于查找具体的类的(实例)方法, 如newflagsm_tbl类定义的实例方法hash, key是方法名或者id, 值是指向方法定义的pointer, 指向处包括已经编译好的方法YARV指令iv_index_tbl类的实例的实例变量映射hash, key 为实例变量名称, 值为在RObject中ivptr的索引
rb_classext_struct
super pointer指向父类, 用于查找继承链上的方法, 读写类变量iv_tbl存储类的实例变量, 以及类变量, 通过前缀@@@来区别const_tbl存储常量origin实现Module#prepend featurerefined_class实现refinementsallocator为新实例分配内存
类变量
-
类变量读写都是沿着super向上查找, 而不会向下查找
class A def self.a @@x end end class B < A @@x = 5 def self.b @@x end end class C < B def self.c @@x end end puts B.b #=> 5 puts C.c #=> 5 puts A.b #undefined method `b' for A:Class
类方法
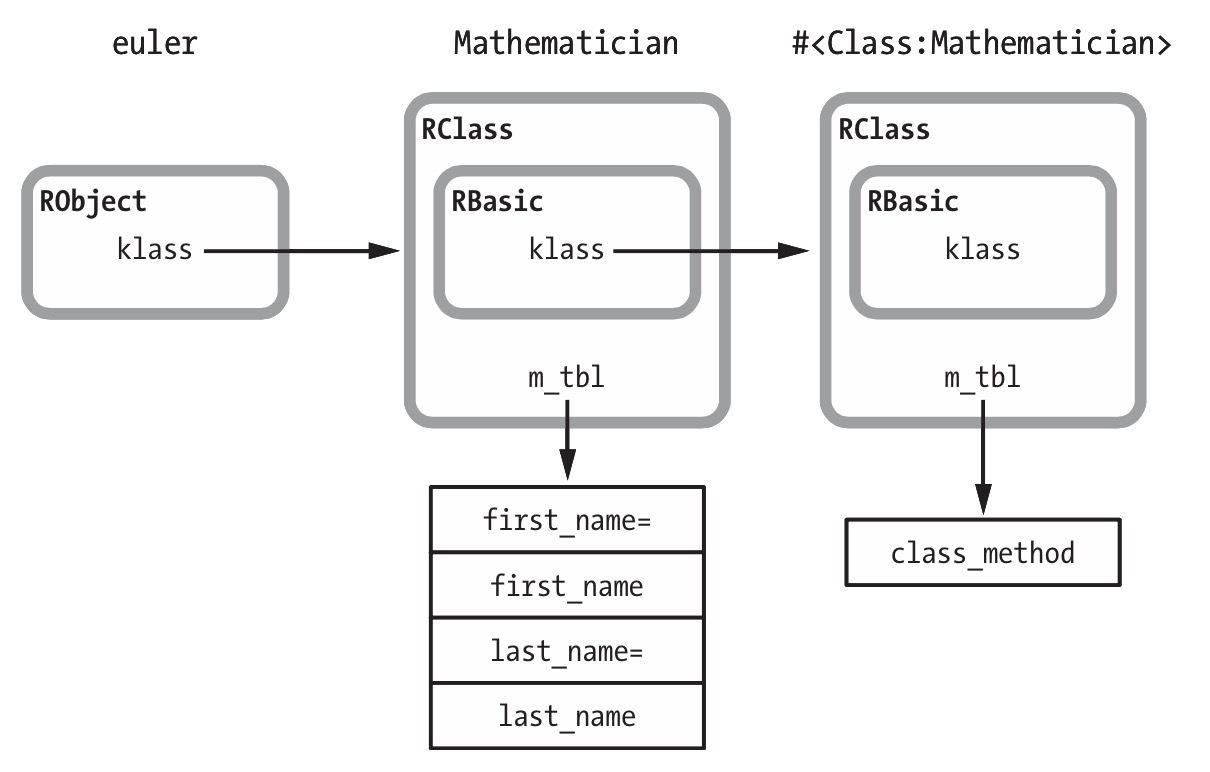
-
每个普通类创建的同时, ruby会同时创建对应的单件类, 普通类的类方法是存于单件类(metaclass)中的
m_tbl> ObjectSpace.count_objects[:T_CLASS] v => 859 > class Mathematician; end => nil > ObjectSpace.count_objects[:T_CLASS] w => 861
6. METHOD LOOKUP AND CONSTANT LOOKUP
Module
A Ruby module is a Ruby object that also contains method definitions, a superclass pointer, and a constants table
- Module 和 Class的区别
- Module实例 不能调用new
- Module实例没有superclass
- Module实例可以被include, Class实例不行
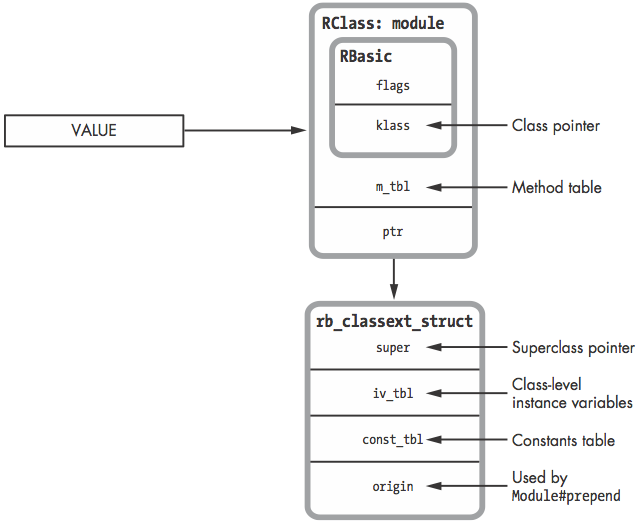
- 和Rclass相比
- 去掉了
iv_index_tbl, 没有实例, 因此不需要实例变量映射表 - 不需要
refined_classallocator - Module 保留了
super, 但是外部不能调用.
- 去掉了
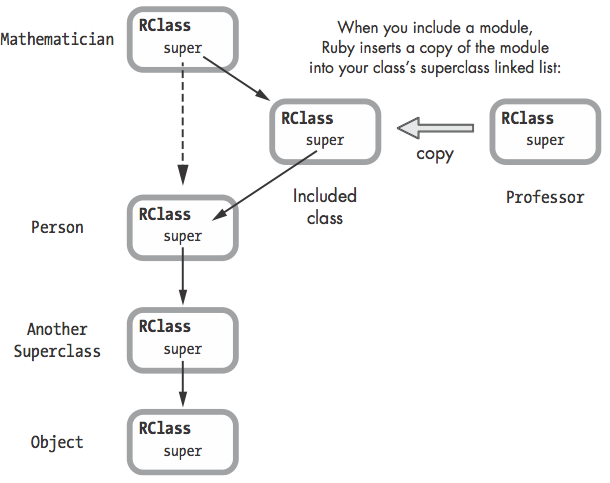
-
被
include的Module会被复制一份, (猜测应该和super相关, 因为Module的super要被改变, 但是Module可以被多个target include) 被复制的Module 的m_tbl指向原来Module的方法表, 因此方法后续可以动态添加 inlucde改变了super的指向- Ruby implements module inclusion using class inheritance. Essentially, there is no difference between including a module and specifying a superclass
- 可以通过多个include实现类似多重继承的功能, 但是内部ruby还是维护的单链super继承
- ruby 方法查找逻辑: terate through the superclass linked list until it finds the class or module that contains the target method
The Global Method Cache
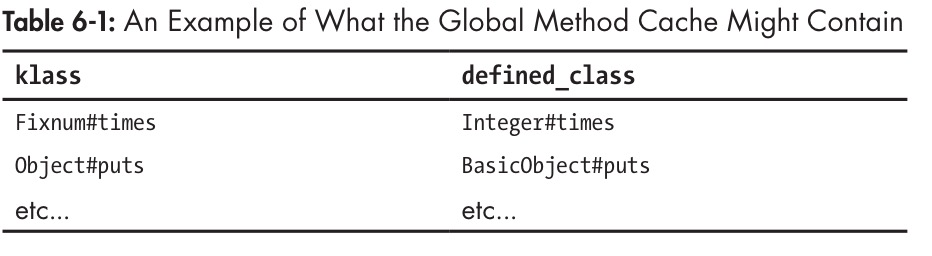
- 出于时间效率考虑, ruby会缓存调用过的方法查找结果, 类似一个hash, key为调用对象的
class#method, 值为defined_class#method
The Inline Method Cache
-
ruby 也会把方法查找结果缓存于YARV指令中
# ruby代码 10.times do... end # 原始YARV putobject 10 send <callinfo!mid:times, argc:0, block:block in <compiled>> # 缓存结果 putobject 10 send Integer#times  - 以下动作会造成方法缓存的清除:
- create or remove (undefine) a method
- include a module into a class
- refinements
- 其他可能的元编程技术
- clearing the cache happens quite frequently in Ruby. The global and inline method caches might remain valid for only a short time
Module#prepend 实现
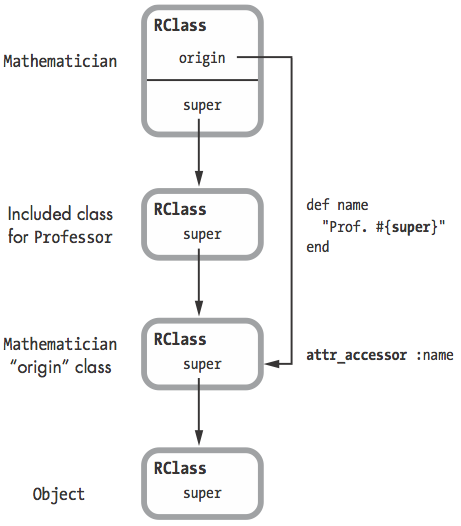
- 首先ruby把prepend按照include实现, 将被prepend的Module插到target的super
- 然后ruby复制target, 作为origin插到prepend的super, target的origin指针指向复制的origin
- 最后ruby把所有target定义的方法, 移动到origin中去
Classes Don’t See Submodules Included Later
module A
def a
puts 'a'
end
end
class B
include A
end
B.new.a # 'a'
module C
def c
puts 'c'
end
end
module A
include C
end
B.new.a # 'a'
B.new.c # undefined method `c' for #<B:0x000001019285b8>
include 的机制是复制Module, 被复制的Module和原始的Module的super后续可以被改变(inlcude其他Module), 从而变得互不相同.
Constant Lookup
Lexical Scope
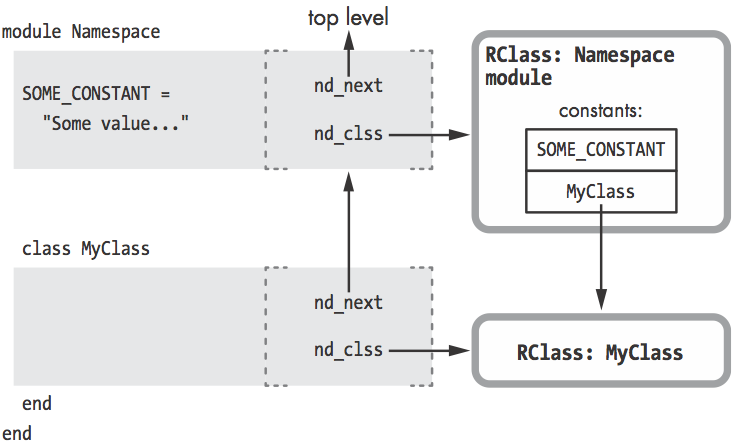
- Ruby在创建RClass的同时, 也创建了对应的词法范围
- 词法范围存在于YARV指令中
nd_next指向上级词法范围nd_clss指向当前类/模块
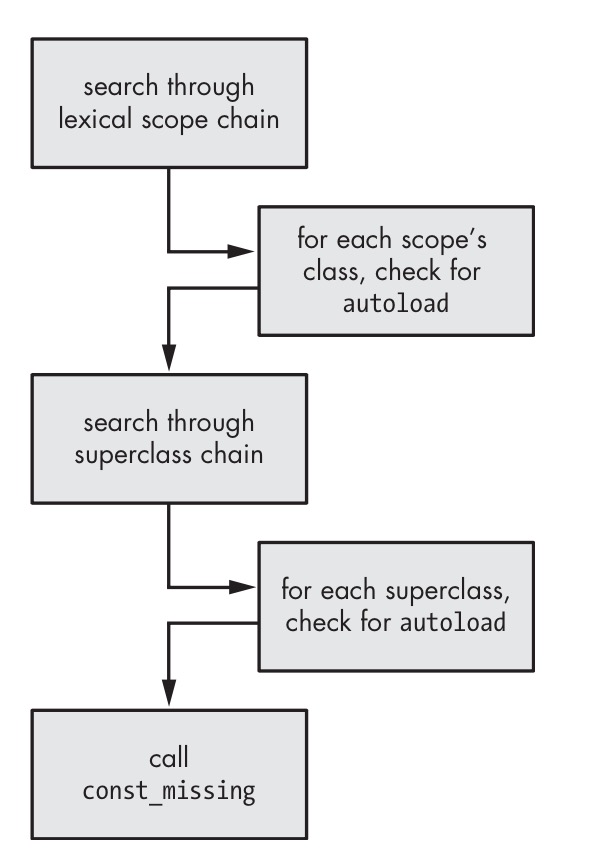
- 先沿着词法范围向上查找(即Module.nesting)
- (如果Module.nesting.first是class的话)然后沿着当前类的super向上查找
7. THE HASH TABLE: THE WORKHORSE OF RUBY INTERNALS
The speed and flexibility of hash tables allow Ruby to use them in many ways
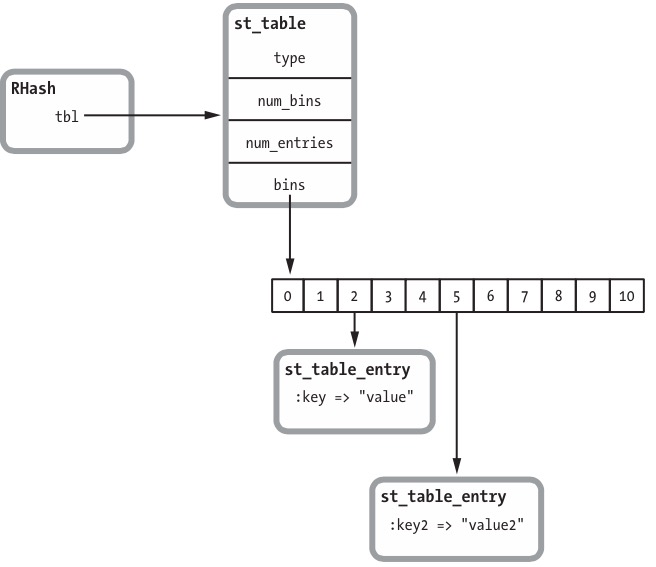
typenum_binsbin 大小num_entries存储键值对个数binsbin指针, 1.9及其以下, 会为新hash创建11个空bin-
hash读写时bin查找算法:
internal_hash_function(key) % num_binsRuby’s hash values are basically ran- dom integers for any given input data
even similar values have very different hash values
-
bins 中各个元素是存储的
st_table_entry链表, 链表中存储的是key的hash值相同的键值对, 对于hash相同的key, 查找需要遍历链表对于同一个bin链表中key的比较, 对于 integers or symbols, which are typically used as hash keys, this is a simple numerical comparison.
其他对象, ruby使用
eql?来判断key是否相等 - Ruby can find and return a value from a hash containing over 1 million elements just as fast as it can return one from a small hash
Hash 冲突
- 多个hash值相同的键值对存于同一个bin的链表里, 称为Hash冲突
-
当hash密度超过5, ruby将会添加更多的bins, 然后Rehash
- ruby 1.8
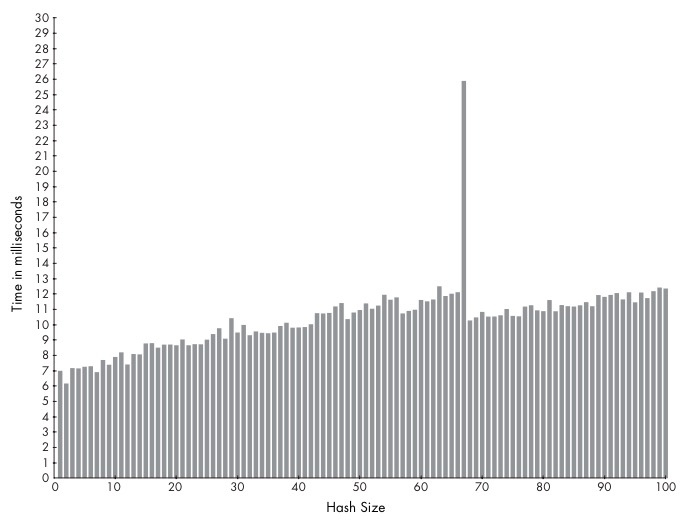
- ruby 2.0
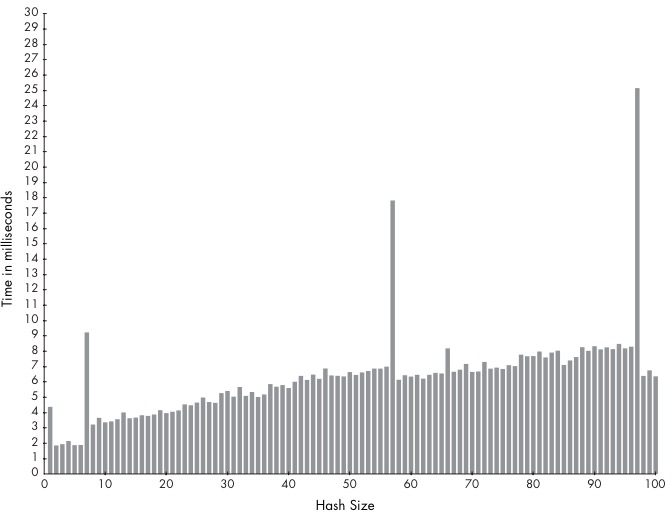
- ruby rehash 阈值都是素数, 能更平均的分散key: 8 + 3, 16 + 3, 32 + 5, 64 + 3, 128 + 3, 256 + 27, 512 + 9 ….
-
源码片段:
#define ST_DEFAULT_MAX_DENSITY 5 出发rehash的密度阈值 #ruby 1.8, 当num_entries是67时, num_bins 是11时, 触发rehash, num_bins将增长为19 if (table->num_entries/(table->num_bins) > ST_DEFAULT_MAX_DENSITY) { rehash(table); #ruby 1.9, 2.0,当num_entries是57时, num_bins是11, 即触发rehash (??应该是56啊, 书上问啥说是57??) if ((table)->num_entries > ST_DEFAULT_MAX_DENSITY * (table)->num_bins) { rehash(table);
Hash 值计算
- 调用Object#hash, 可以在子类中覆盖
- Object#hash 使用RValue的内存地址, 传入C函数, 获得一个随机值.
- 特定的, 对于strings and arrays, ruby会遍历他们的元素, 计算一个累积的hash值, 用以保证对不同对象, 相同内容的string或者array,得到相同的hash值
- 特定的, 对于Integers and symbols, ruby直接把其值传入C hash函数
- ruby 1.9, 2.0 C hash函数采用MurmurHash, 初始化时需要一个随机seed, 因此同一ruby进程的同一对象hash值始终相同, 但是不同进程的对象hash值将会变化
ruby 2.0 packed hash
-
ruby 2.0 对于hash键值对小于等于6个的, 不使用bin, 直接将键值对存于entries, 查找是遍历查找
Ruby iterates through the array and calls the eql? method on each key value if the values are objects. For simple values, such as integers or symbols, Ruby just uses a numerical comparison
-
键值对大于6后, ruby 2.0会使用之前的bin方式, 这也说明ruby 2.0 为什么第七个插入较慢.
12. GARBAGE COLLECTION IN MRI, JRUBY, AND RUBINIUS
- MRI: mark-and-sweep GC 标记清除
- JRuby and Rubinius: copying GC 复制
- MRI 2.1: generational GC 分代
标记清除
GC 的作用
- 为新对象分配内存
- 标识哪些对象不再使用
- 回收不再使用的对象内存
free list

- MRI 维护多条
free list, 每条大概16k (24 lists of 407 objects each) - 每个内存块存储一个RVALUE, 总共可以存储大概10000个RVALUE, MRI 逐条遍历free list, 直到所有list用完
-
RVALUE 内部使用union使之能包括所有MRI对象的数据结构, 如 RArray, RString, RRegexp等
In other words, each square could be any kind of Ruby object or an instance of a custom Ruby class (via RObject).
The contents of each object, such as the characters in a string, are often stored in a separate memory location.
Marking
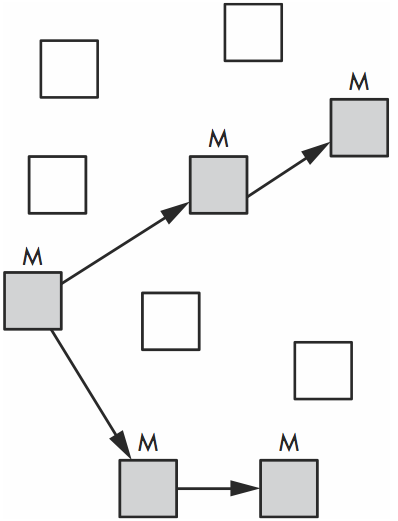
free list如果满了, GC将导致用户程序停止, 进行标记清除, 如果没有垃圾对象可以清除重用, ruby 将向系统申请新的内存, 如果无内存可用, 将抛出异常out-of-memory
Bitmap Marking

(ruby 1.9 之后)free bitmap 独立于对象结构内存之外存储, 原因是避免GC影响进程复制时的copy-on-write优化
Sweep
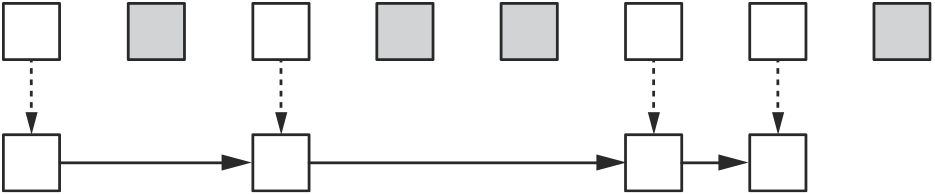
RVALUE

Lazy Sweeping
从ruby1.9.3起, ruby只清除一定量的垃圾对象到free list, (标记还是全量), 使得程序因为GC而造成的单次停顿变短, GC 之后会分期完成清除, 所有总的清除消耗不变
标记清除的缺点
- 程序因为GC运行而停顿
- 时间性能: 标记需要遍历所有对象, 清除需要遍历所有垃圾对象
- 所有对象内存大小需要一致(RVALUE)
ObjectSpace.count_objects
=> {:TOTAL=>92114, # 所有free list 总大小
:FREE=>431, # 空闲空间大小, 包括被标记为垃圾对象的空间, 不管是否清除
# 每创建一个RObject, 还要创建6个其他对象, 因此占用7个free
:T_OBJECT=>5809, # 当前存活的RObject 和垃圾对象个数
:T_CLASS=>884,
:T_MODULE=>31,
:T_FLOAT=>4,
:T_STRING=>58905,
:T_REGEXP=>185,
:T_ARRAY=>14668,
:T_HASH=>435,
:T_STRUCT=>2,
:T_BIGNUM=>2,
:T_FILE=>10,
:T_DATA=>1553,
:T_MATCH=>707,
:T_COMPLEX=>1,
:T_NODE=>8450,
:T_ICLASS=>37
}
- 当遇到ruby2 lazy sweep时, FREE大量增长(全量标记),
T_OBJECT清除一个, (新对象)马上占用一个 -
GC.start可以出发全量sweep, FREE大量增长,T_OBJECT大量下降 GC::Profiler.enable开启GC报告-
GC::Profiler.report展示GC报告Invoke timeGC 启动时间点, 从ruby脚本执行开始算Use sizeGC结束后, 存活对象占用的堆内存Total sizeGC结束后, 存活对象和free list占用的堆内存Total object存活对象和free list中的所有对象个数GC Time本次GC耗时
-
随着存活对象增加, ruby会倍增
Total size, 因为GC是在free list满了触发的, 因此下次GC的启动间隔将会指数增长也就是随着存活对象的增加,
Invoke time时间间隔,Use size,Total sizeTotal objectGC Time都将成倍增长the time required to perform a garbage collection increases lin- early as a function of the total heap size
Garbage Collection in JRuby and Rubinius
-
JRuby/Rubinius GC 特点
- 不使用free list, 使用 copying garbage collection
- generational garbage collection
- concurrent garbage collection
-
Mruby 2.1 增加了 generational 和 concurrent GC 特性
Copying Garbage Collection
-
Bump Allocation

- 在连续的大内存区块进行对象内存分配
- 有一个指向下次分配起始地址的指针
- 对象占用内存大小可以不一致
优势:
- 简单
- 快
- 内存局部化(对缓存友好)
- 对象只分配相应的大小
-
The Semi-Space Algorithm
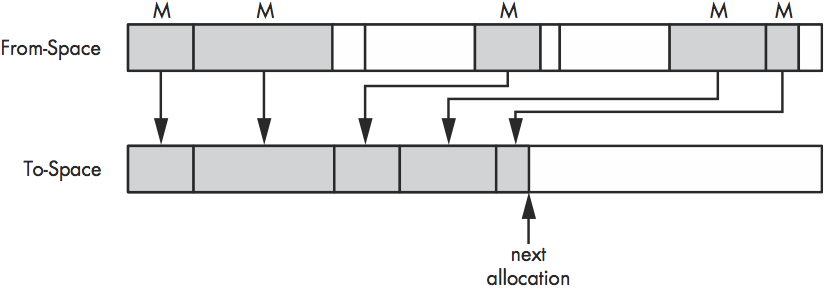
- 维护
From-Space和To-Space - 当
From-Space满了, GC开始 - 遍历
From-Space, 标记存活对象 - 复制
From-Space中的存活对象到To-Space, 并连续存储 From-Space和To-Space角色反转
优势: 内存友好
劣势: 有时效率低(存活对象多次分配内存), 实现复杂(内部需要更新对象引用地址)
- 维护
-
The Eden Heap
- 除了
From-Space和To-Space, 增加Eden heap - 每次GC, 把
From-SpaceEden heap中的存活对象复制到To-Space, 然后From和To反转 - 每次GC后,
Eden heap都是空的, 老对象都在From-Space - 每次创建新对象, 都放到
Eden heap
- 除了
Generational Garbage Collection
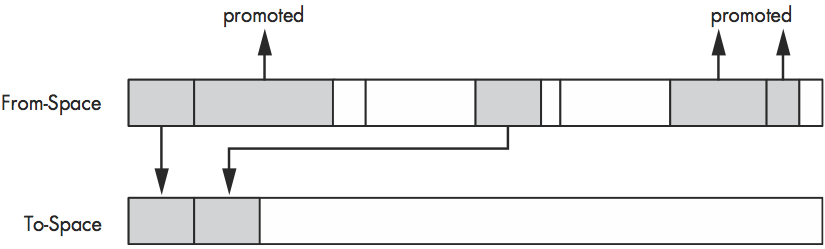
-
分类:
- mature
- young
-
理论: weak generational hypothesis
新对象存活期较短, 老对象存活期较长
-
分代依据: 存活对象经历的GC次数
-
对象晋升:
当young对象GC次数超过
new object lifetime后, 将晋升为mature对象 -
不同的分类将有不同的GC机制
-
young: minor collection
The Semi-Space Algorithm
young对象存活率低, 当Eden Heap满了, 需要GC时, Eden Heap复制的内容较少
-
mature: major collection
mature 对内存满了后, 会触发GC, 因为mature对象较少, mature的GC频率较少
-
- JVM运行用户设置 young, mature堆内存大小, 同时还维护了第三个分类
permanent -
Rubinius同样维护了第三个分类, 存放存活周期非常长的对象, 使用标准的标记清除
-
MRI Ruby 2.1 引入和JRuby/Rubinius类似的分代GC
-
mature 引用 young 问题
背景: 因为minor GC 只标记young对象, 不遍历mature对象
问题: mature 引用 young对象如何标记为存活?
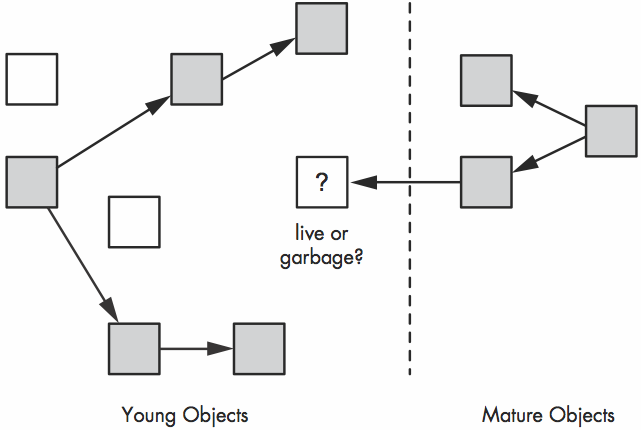
Mruby 解决方案: Write Barriers
跟踪mature 引用 young对象, 对于此种mature对象, 作为minor GC的一个root就行标记
参考资料
- http://patshaughnessy.net/ruby-under-a-microscope
- http://bachue.github.io/ruby-under-a-microscope-introduction-slides/